
[ad_1]
What Had been Google Cached Pages?
Google cached pages have been Google’s information of how pages appeared after they have been final listed.
You can entry a cached web page by doing a Google seek for the web page’s URL. And clicking the three vertical dots subsequent to its search outcome on the search engine outcomes web page (SERP).
An “About this outcome” panel offering extra details about the web page would seem. You can then click on the panel’s “Cached” hyperlink button:
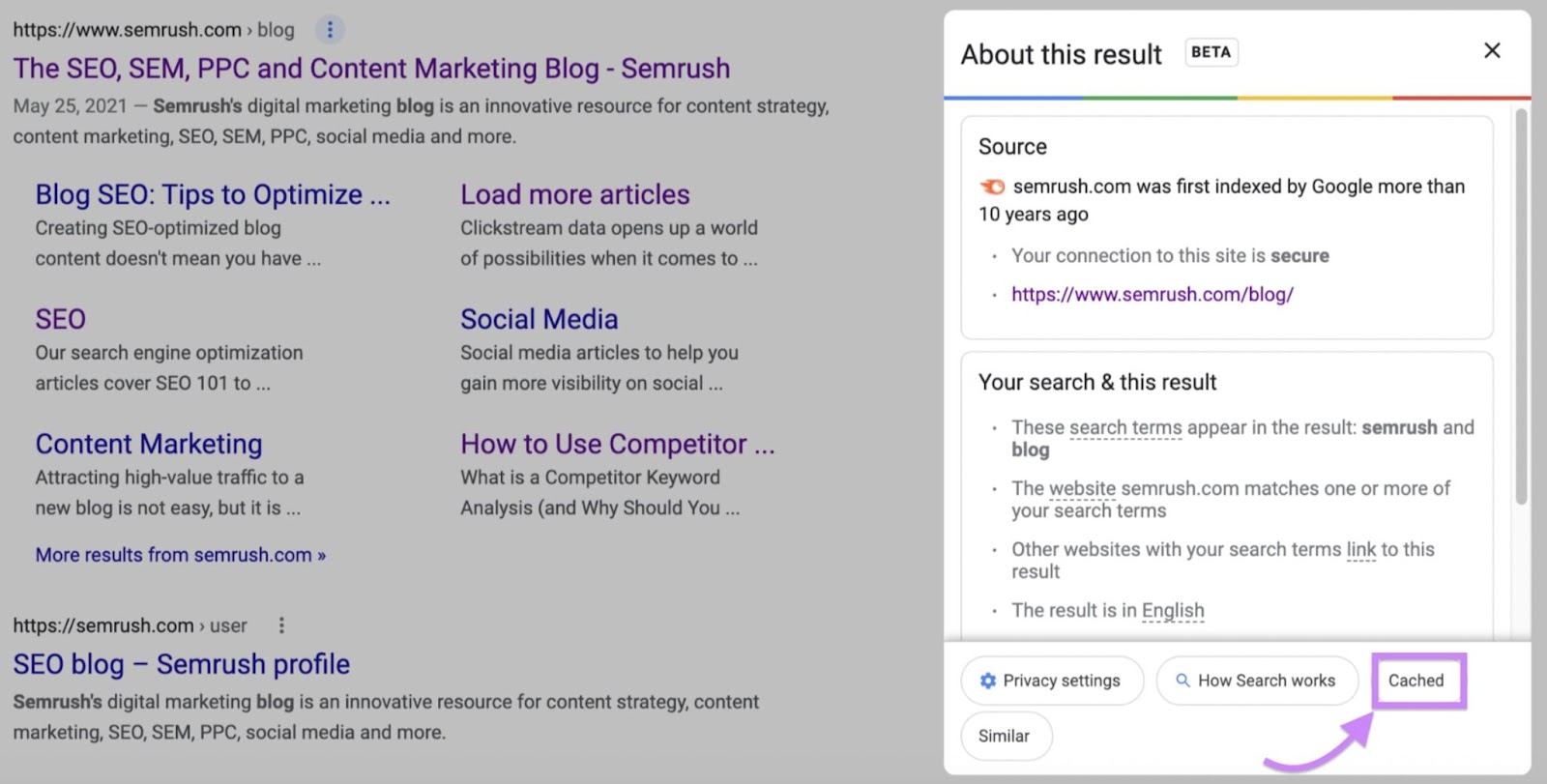
And Google would present you its cached model of the web page as of a sure date and time.
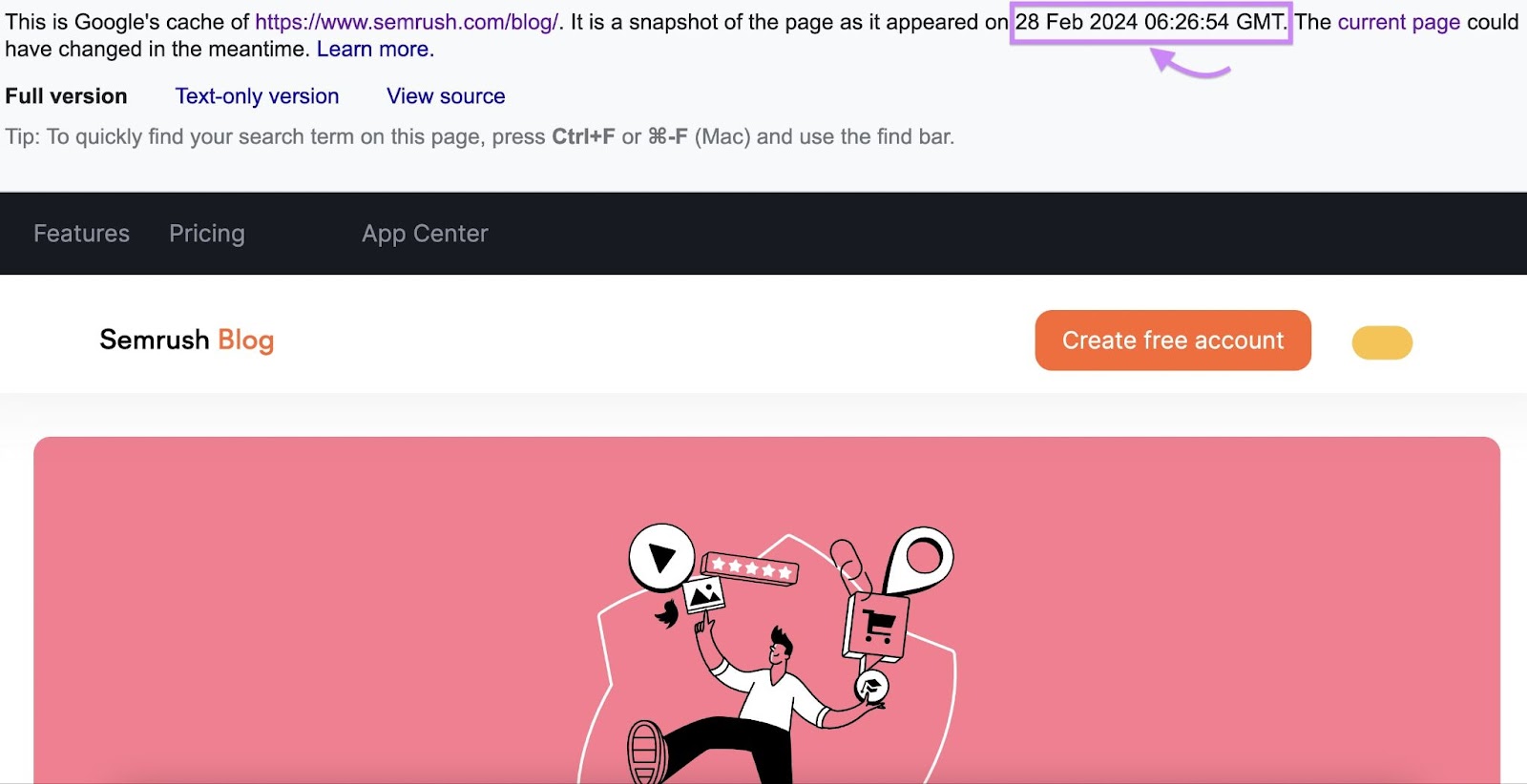
You can additionally entry Google’s cached model of a web page by including “cache:” earlier than the web page’s URL in your browser deal with bar.
Like so:

In February 2024, Google confirmed its removing of the “Cached” hyperlink button from its search outcomes’ “About this outcome” panels. Because of this, customers can not entry Google’s cached pages from its SERPs.
Including “cache:” earlier than the web page’s URL in your deal with bar nonetheless works. However Google will even be disabling this function quickly.
Why did Google cache pages? Why is it eradicating entry to them now? And what alternate options do you’ve gotten, in gentle of this modification?
Let’s discover out.
The Rationale for Google Caching
Google’s “cached” function was greater than 20 years previous.
Right here’s how the Google SERP appeared on Dec. 3, 2000, for instance. Try the “Cached” hyperlink for every search outcome:
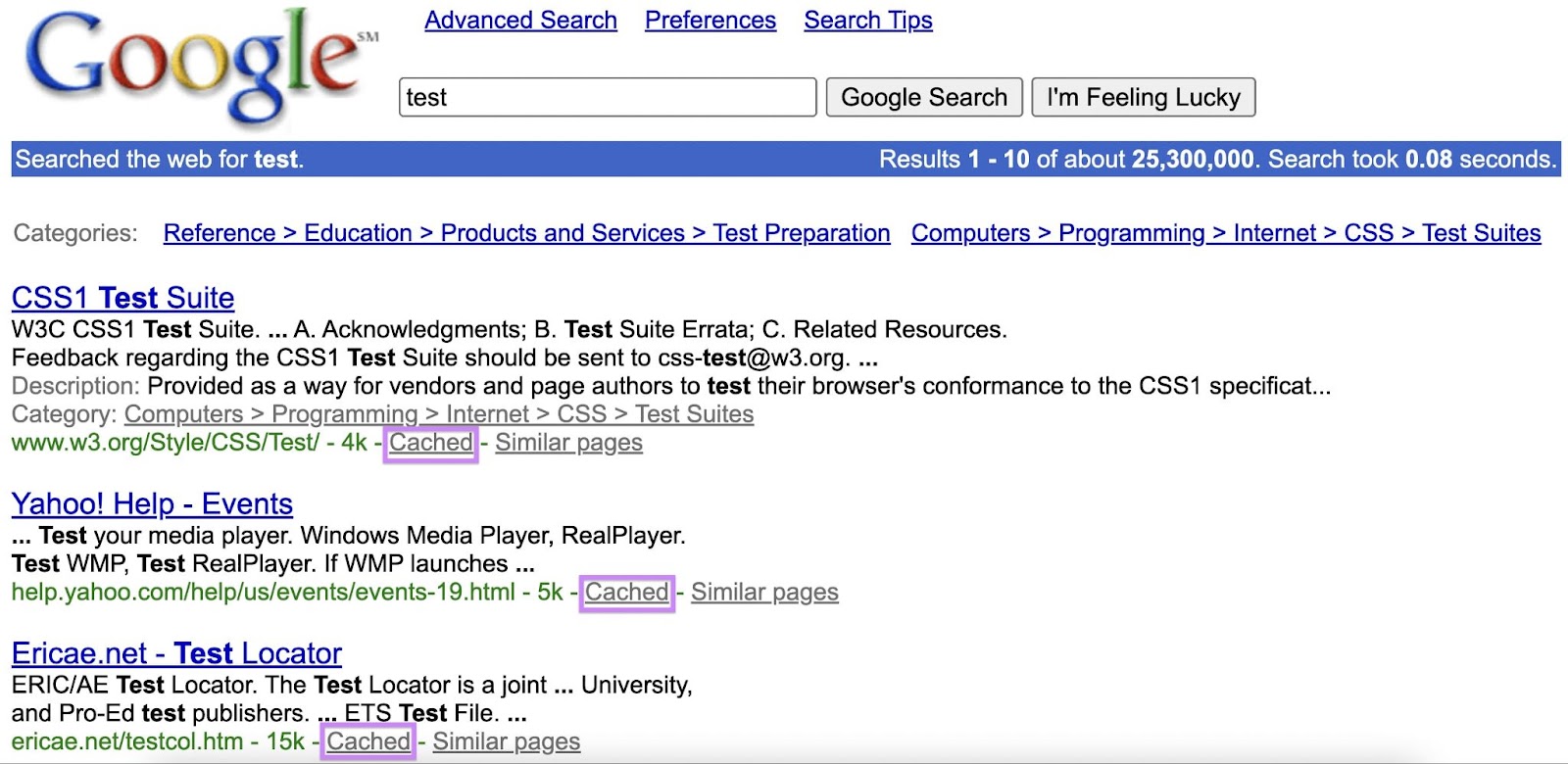
And over these previous 20-plus years, the function performed an vital position.
Why Did Google Cache Pages at All?
Google cached pages to assist customers view unavailable webpages.
These pages could possibly be unavailable as a result of causes like:
The web site’s server was down The web site’s server was overloaded with site visitors The web page was taking too lengthy to load
So, if a consumer couldn’t entry a web page itself, they may view Google’s cached web page as a substitute. And get the knowledge they wished.
The Significance of Google Cached Pages to Web site House owners
Google cached pages primarily for customers’ profit. However web site homeowners may additionally use the cached pages to verify whether or not Google had listed their pages appropriately.
When Google indexes a web page, it saves a duplicate of the web page in its search outcomes database, or index—which isn’t publicly accessible. It additionally saved one other copy of the web page in its cache—which was publicly accessible.
Resulting from limitations in Google’s caching skills, Google’s cached model of a web page could not have been equivalent to the model of the web page in Google’s index. Nevertheless it was nonetheless an excellent approximation.
So, though web site homeowners couldn’t—and nonetheless can’t—verify how their web page seems in Google’s index, they may nonetheless verify the way it appeared in Google’s cache. Doing this, they’d get steerage on how the search engine noticed their web page when indexing it.
If Google’s cached model of the web page appeared considerably totally different from what the web site proprietor meant, its listed counterpart may not be what they meant, both.
The web site proprietor may then take motion to enhance their web page. And have Google reindex it after that.
That means, Google would replace the model of the web page in its index, and show that up to date web page in response to related search queries.
The Discontinuation of Entry to Google Cached Pages
Google Search Liaison Danny Sullivan confirmed in an X (previously Twitter) submit on February 2, 2024, that the search engine had eliminated the “Cached” hyperlinks from its SERPs:
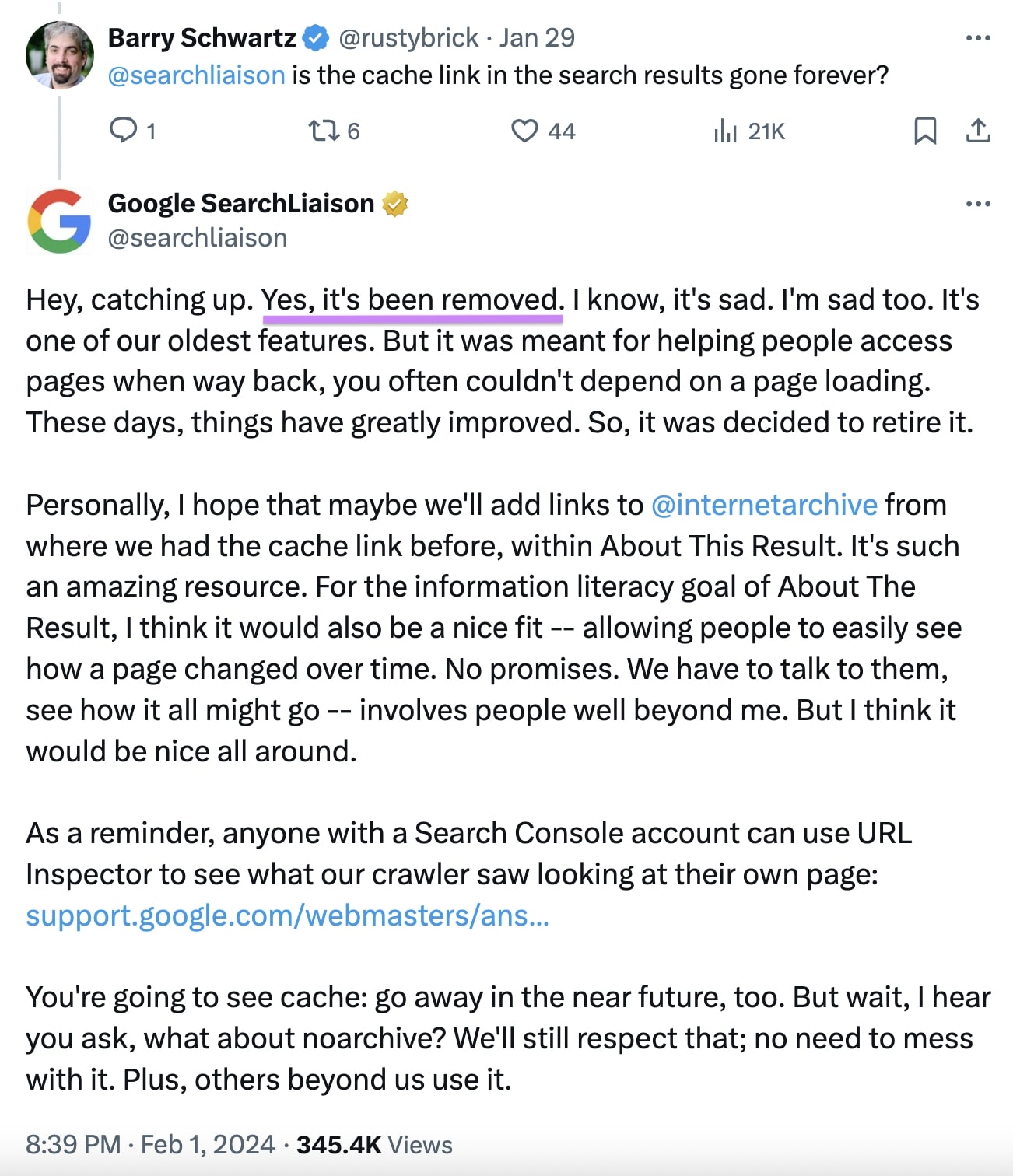
Within the submit, Sullivan defined that Google initially offered the function greater than 20 years in the past to assist customers entry pages.
At the moment, web site expertise was extra primitive. And web speeds have been slower.
The outcome?
Web sites didn’t all the time load reliably.
However expertise has improved through the years. Now, Google believes customers face fewer points making an attempt to go to web sites.
So, it determined to discontinue its “Cached” hyperlinks. It should additionally “within the close to future” stop customers from utilizing the “cache:” methodology to entry its cached pages.
Impression of Discontinuing Entry to Google Cached Pages
Google’s determination to take away entry to its cached pages will have an effect on varied stakeholders:
Customers
Customers will not have the ability to use Google’s “cached” function to:
View unavailable pages. They will’t click on the web page’s “Cached” hyperlink on the Google SERP to entry its cached model. Bypass article paywalls. Customers may beforehand use the cached pages to learn sure paywalled articles at no cost. However not anymore.
web optimization Professionals
web optimization professionals could encounter extra issue:
Checking whether or not Google has appropriately listed their web page Checking when Google final listed their web page. They will not get this info by referring to the cached model’s timestamp. Conducting competitor analysis. E.g., evaluating a competitor’s reside web page with its cached model to establish adjustments to its content material. Particularly if the competitor’s web page had not too long ago gotten an enormous rankings enhance. Figuring out misleading cloaking exercise. A web site proprietor could have given search engines like google one model of a web page to index and rank and used redirects to indicate customers a considerably totally different web page. If that’s the case, Google’s cached model of the web page may uncover the deception by revealing what the search engine noticed when indexing it.
Net Builders
Net builders will want various instruments for:
Recovering misplaced content material. This could possibly be content material from a web page that had gone down. Or content material that they’d forgotten to again up earlier than updating the web page. Both means, they may have accessed Google’s cached model of the web page—assuming it nonetheless contained the required content material—to retrieve what had been misplaced. Troubleshooting web site code. Net builders may use Google’s cached pages to verify how the search engine rendered their webpages. Variations between the rendered and meant pages’ appearances may point out code errors. Even when the web site appeared “regular” to customers.
Options to Google Cached Pages
Google’s “cached” function isn’t the one possibility for viewing previous variations of pages. Listed here are some alternate options.
URL Inspection Instrument
You should use the URL Inspection Instrument solely on the pages of internet sites to which you’ve gotten admin entry. To verify how Google has listed pages on different web sites, use the Wealthy Outcomes Take a look at instrument as a substitute.)
The URL Inspection Instrument is a Google Search Console (GSC) instrument for getting info in your web site’s Google-indexed pages. This info contains:
The date and time Google final crawled (i.e., visited) the web page Whether or not Google may index the web page How Google noticed the web page when indexing it
The URL Inspection Instrument offers extra correct insights into how Google has listed a web page than Google’s cached pages.
That’s as a result of in contrast to Google’s caching options, the URL Inspection Instrument doesn’t have bother processing JavaScript code. So, it may well extra precisely present how Google sees your listed web page—particularly if its look is influenced by JavaScript.
To make use of the URL Inspection Instrument in your pages, log in to GSC. (Arrange GSC in your web site first in case you haven’t already.)
There’s a search bar on the high of each GSC display screen. Sort—or copy and paste—the URL of the web page you wish to verify.
Then, press “Enter” or “Return” in your keyboard.
Google will retrieve knowledge in your web page from its index. If it has listed your web page, you’ll see the message “URL is on Google.”
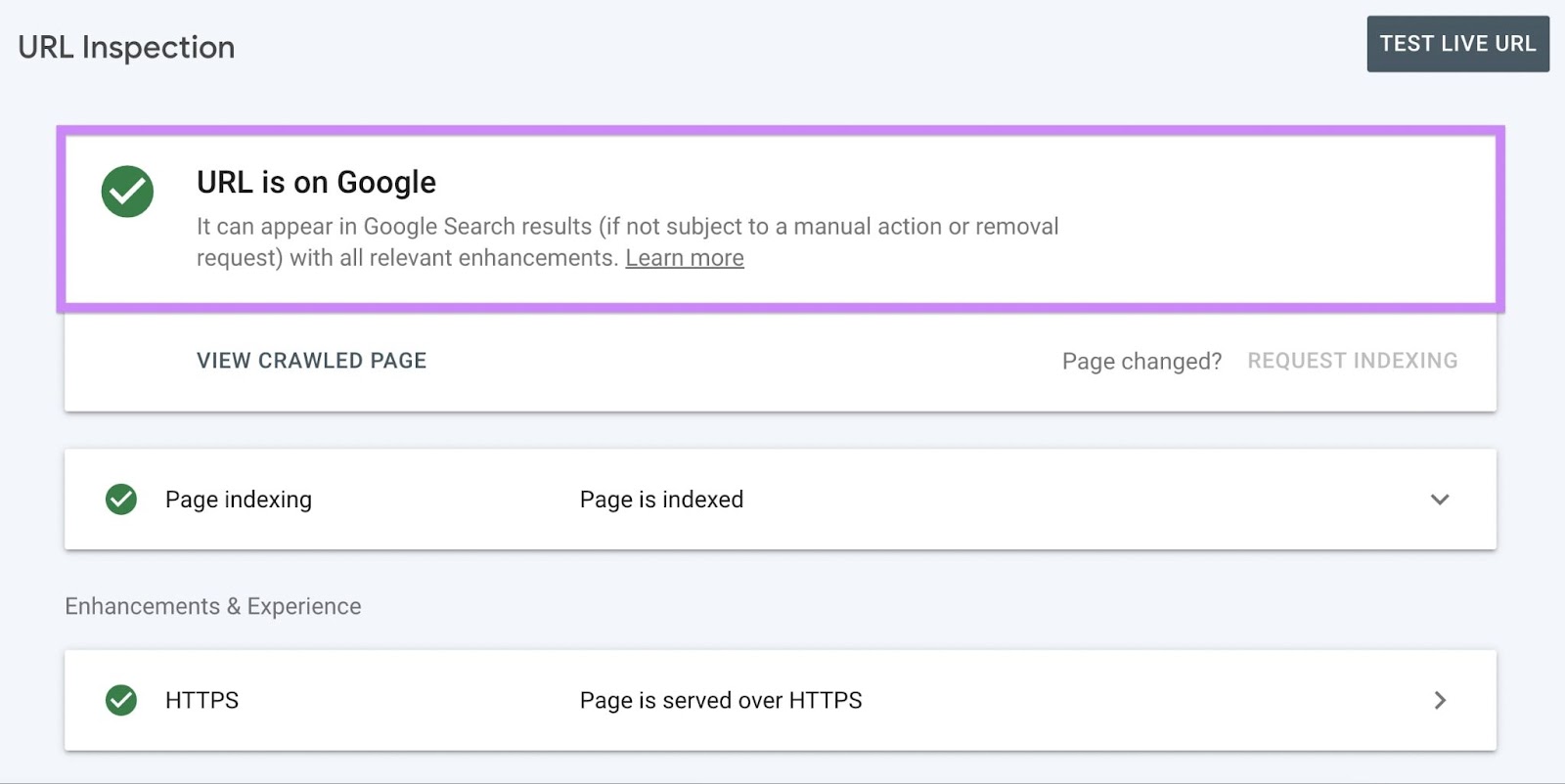
Click on “View crawled web page” to see the Hypertext Markup Language (HTML) Google has detected in your web page.
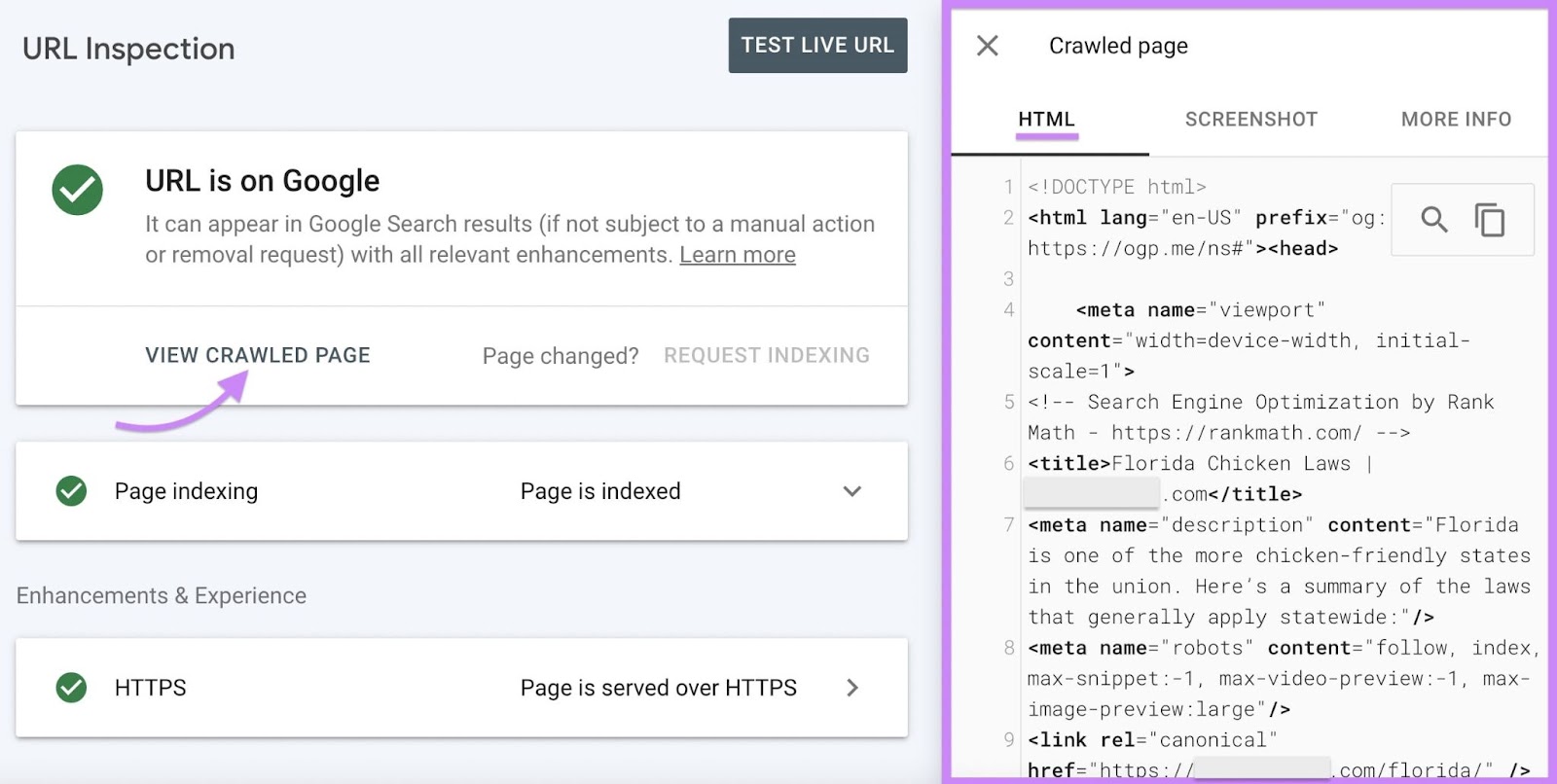
Alternatively, click on the “Web page indexing” drop-down menu to be taught the date and time Google final crawled your web page.
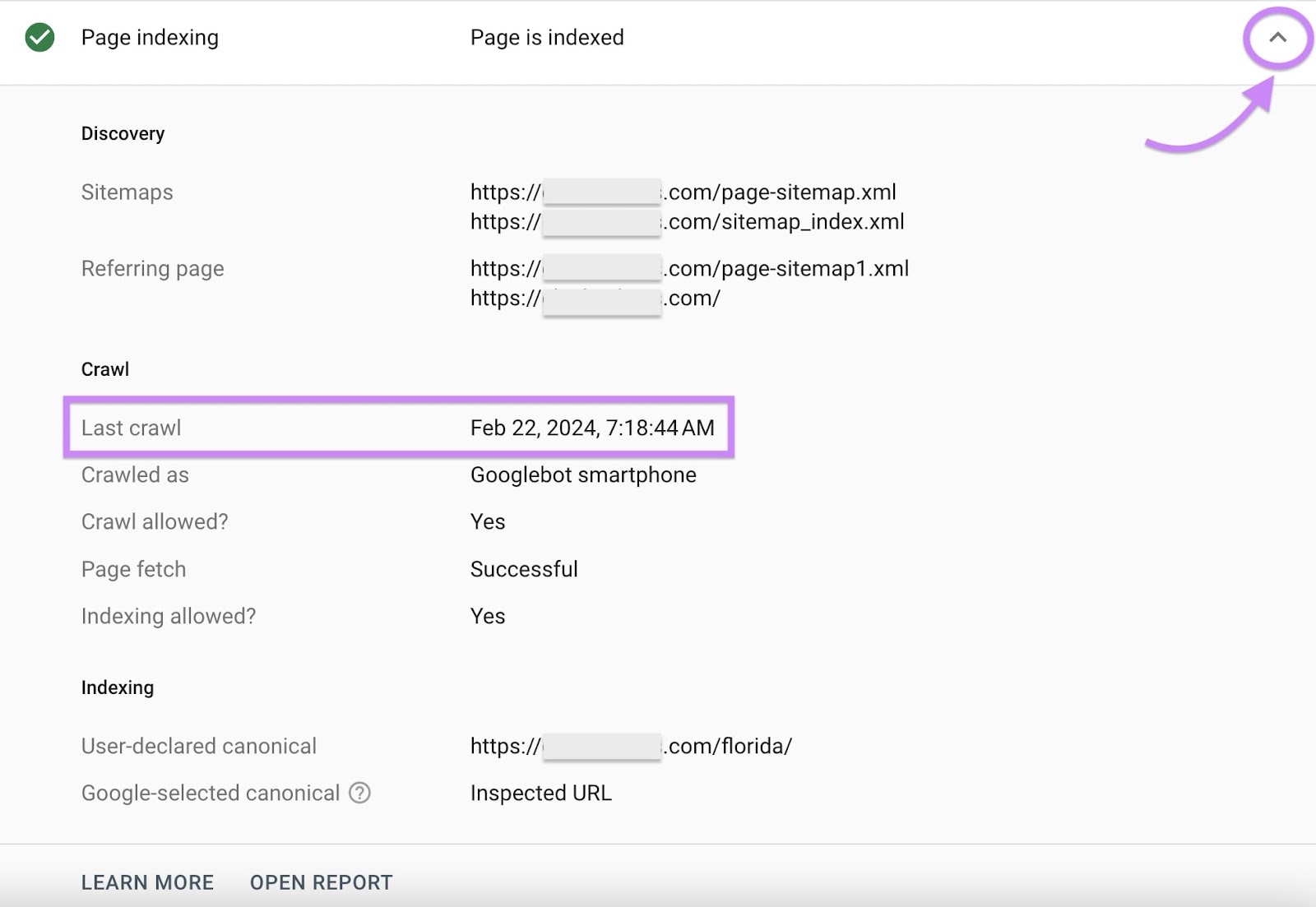
To view how Google sees your web page, click on “Take a look at reside URL.”
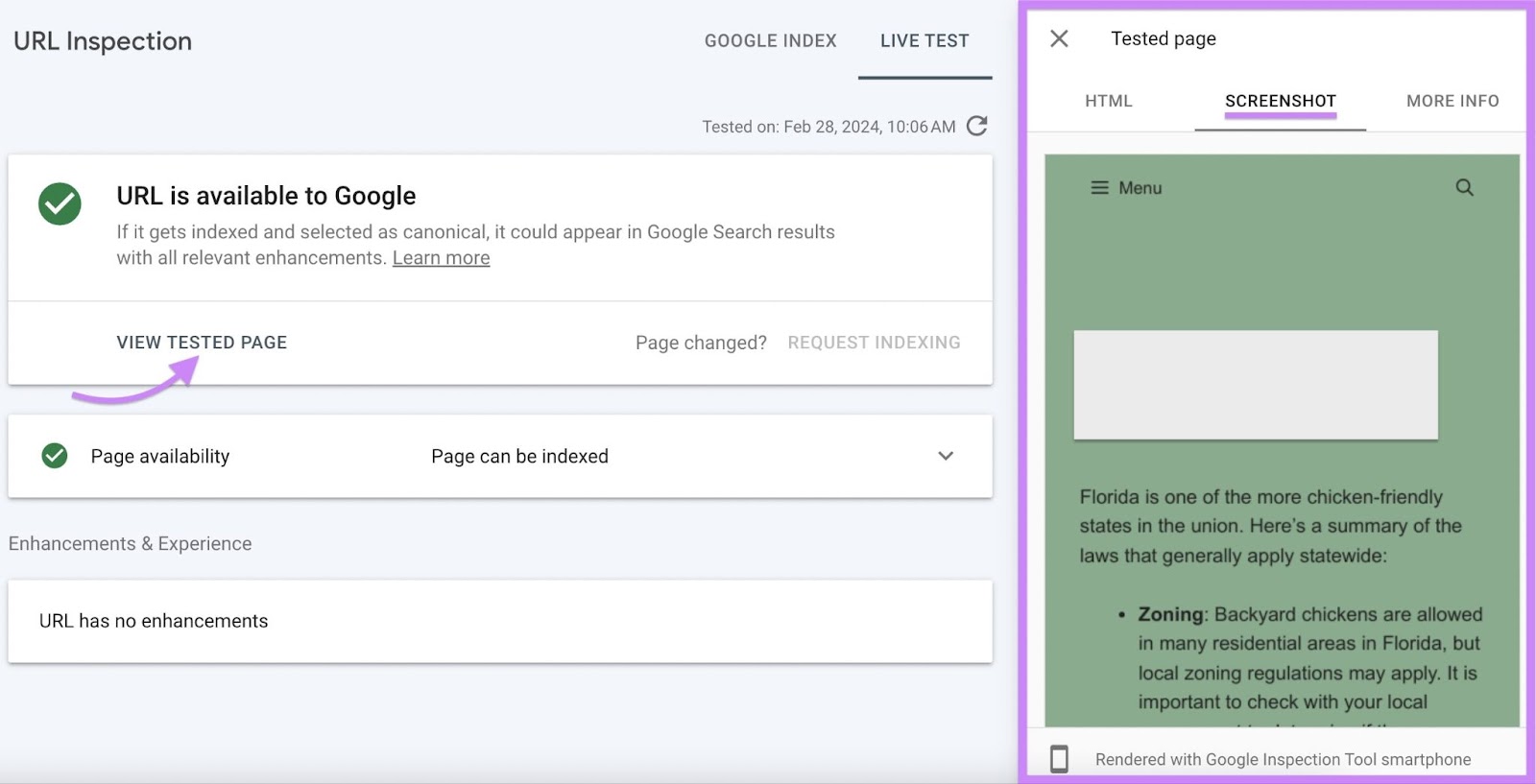
Google will check your web page’s URL in actual time. When the check is full, click on “View examined web page” > “Screenshot.” You’ll see a piece of your web page’s present look to Google.
The URL Inspection Instrument’s outcomes for listed and reside URLs could differ in case your web page has modified since Google’s final indexing of it.
Let’s say you beforehand added the “noindex” tag to your web page to forestall Google from indexing it. However you latterly eliminated this tag to make your web page indexable.
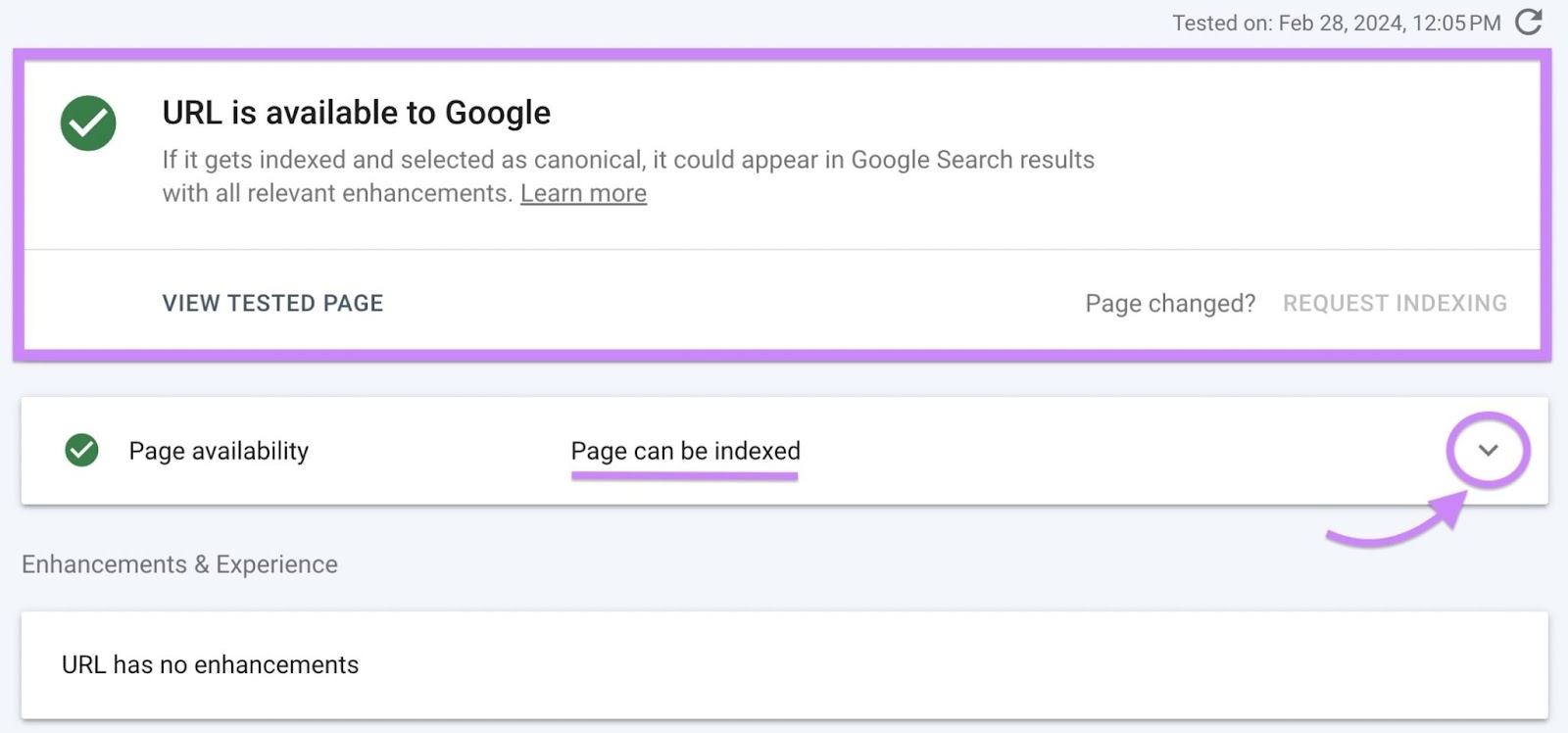
If Google hasn’t recrawled your web page after this removing, it received’t have detected the change. So, the URL Inspection Instrument will nonetheless report your web page’s “Web page indexing” standing as being “Web page is just not listed: URL is unknown to Google”:
However whenever you live-test your web page’s URL, the instrument will report your web page’s “Web page availability” standing as “Web page will be listed” as a substitute.
Wealthy Outcomes Take a look at Instrument
Developed by Google, the Wealthy Outcomes Take a look at instrument allows you to live-test a web page for wealthy outcomes—particular content material that helps it stand out on the SERP. Within the course of, the instrument can present particulars like:
The date and time Google final crawled the web page Whether or not Google may crawl the web page How Google noticed the web page when crawling it
The URL Inspection Instrument gives related info. However the Wealthy Outcomes Take a look at instrument differs in these methods:
The Wealthy Outcomes Take a look at instrument crawls pages’ reside URLs in actual time. In contrast to the URL Inspection Instrument, it may well’t retrieve current web page knowledge from Google’s index. You may verify any web page URL utilizing the Wealthy Outcomes Take a look at instrument. The URL Inspection Instrument limits you to checking the web page URLs of internet sites you’ve gotten admin entry to.
Use the Wealthy Outcomes Take a look at instrument by navigating to search.google.com/check/rich-results. Sort—or copy and paste—the URL you wish to check into the search bar.
Then, click on “Take a look at URL.”
Below “Particulars,” you’ll see:
Google’s crawl standing for the web page, e.g., “Crawled efficiently” or “Crawl failed” The date and time of the (un)profitable crawl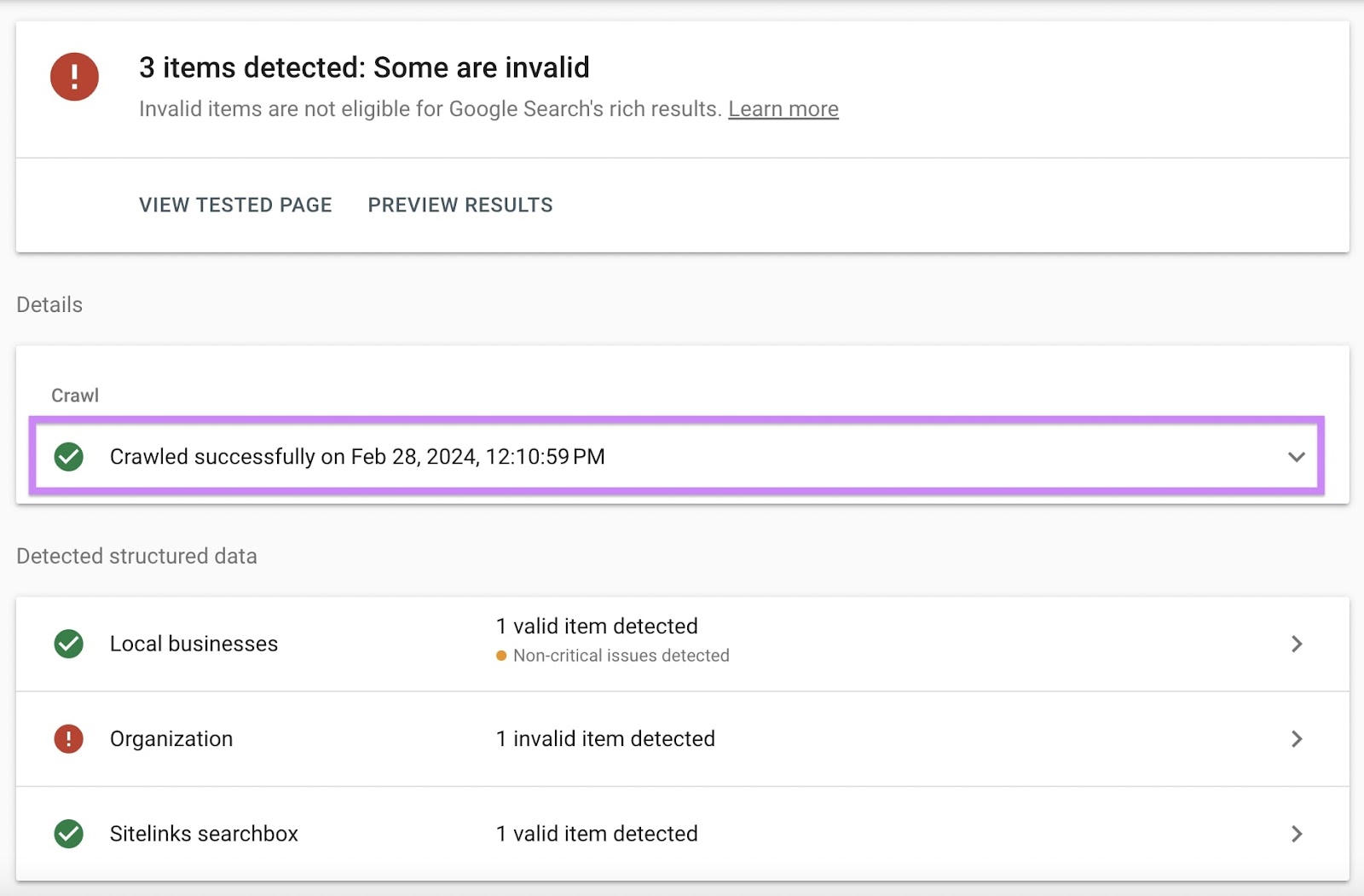
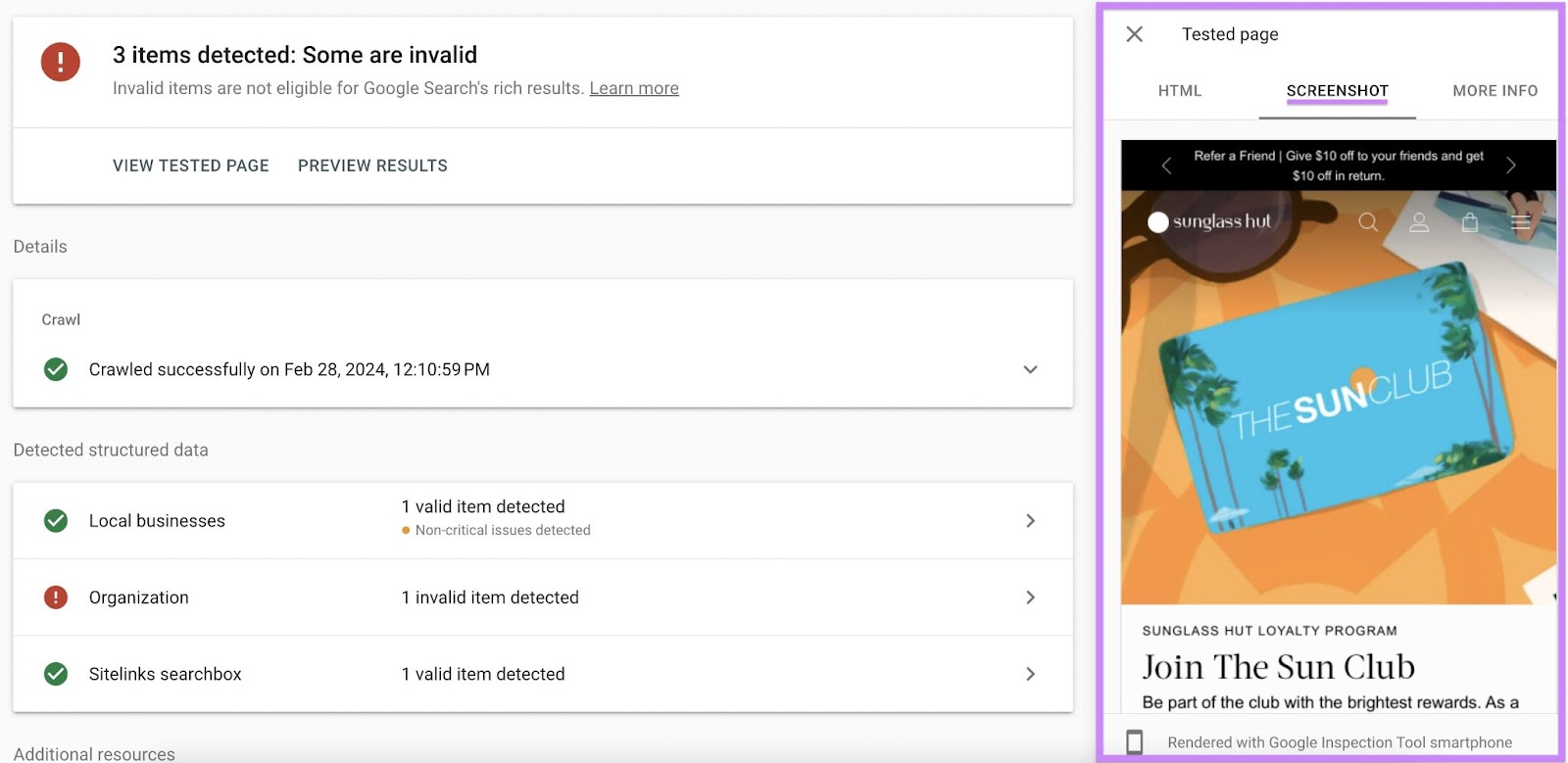
To view how Google noticed your web page whereas crawling it, click on “View examined web page.”
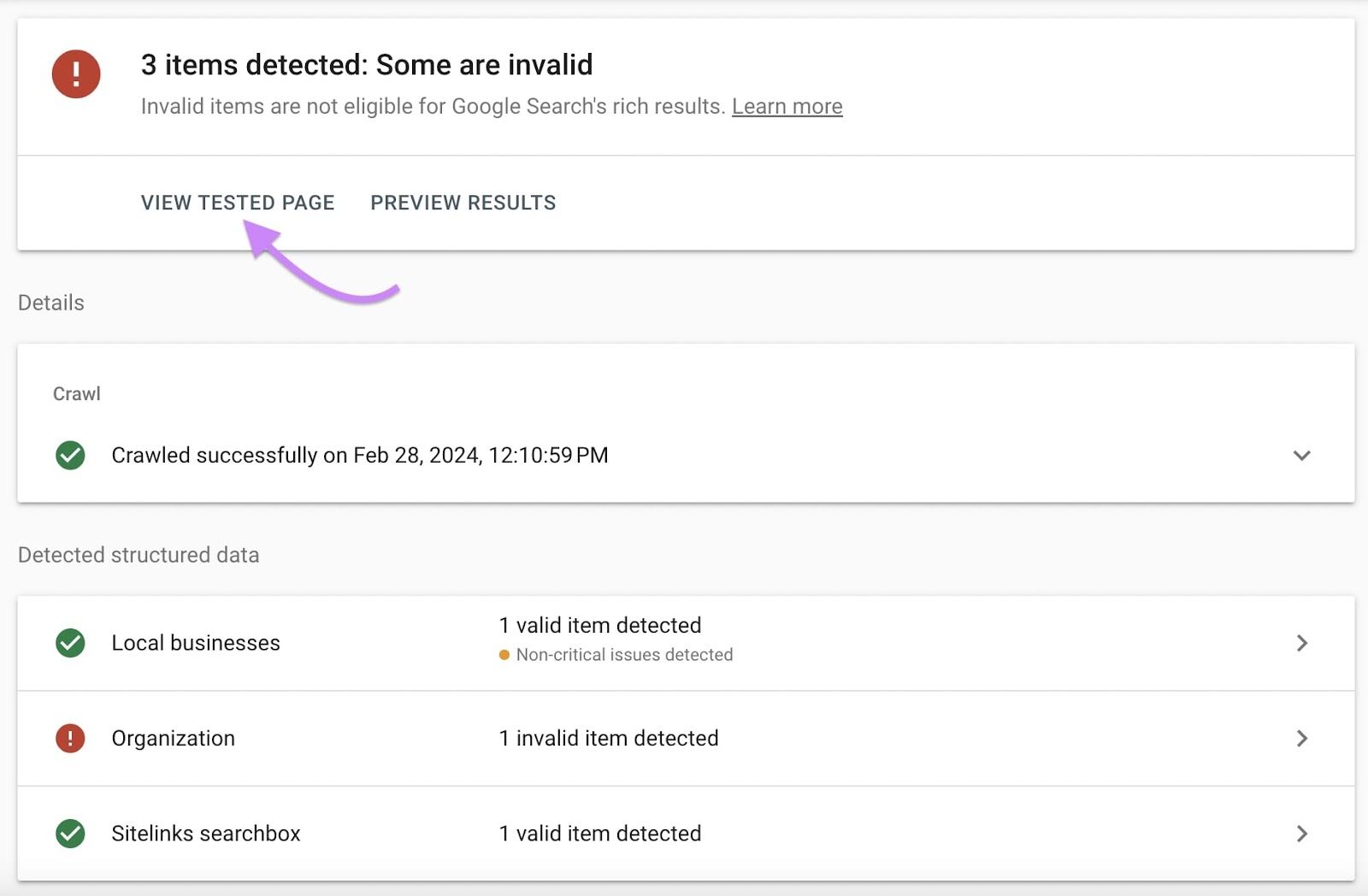
A panel will seem on the precise. Its “HTML” tab exhibits you the HTML Google detected on the web page:
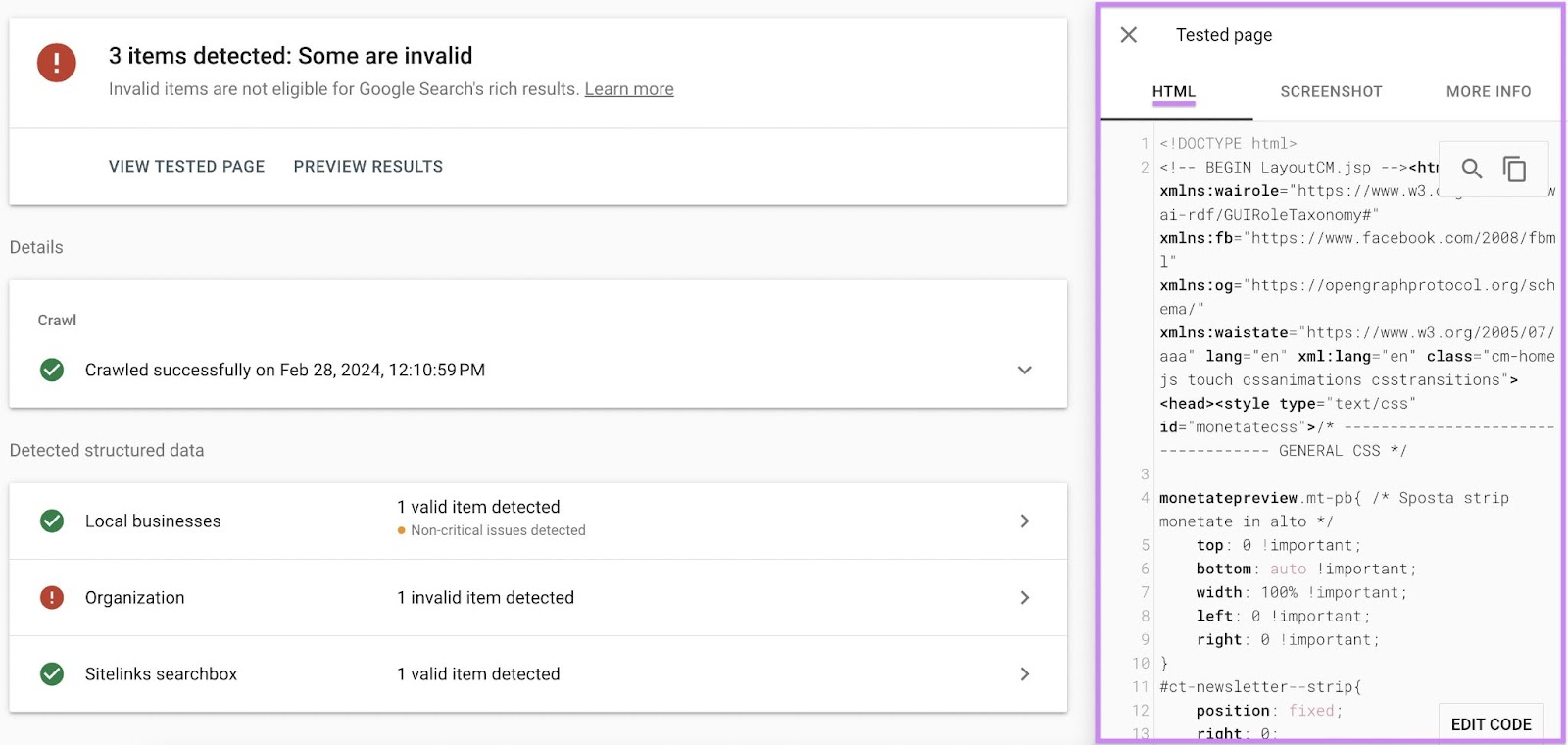
Click on the “Screenshot” tab to view a piece of your web page’s present look to Google.
Different Search Engines’ Caches
Whereas Google could have disabled entry to its cached pages, different search engines like google additionally cache pages. And proceed to permit entry to them.
These search engines like google embody Bing and Yahoo!.
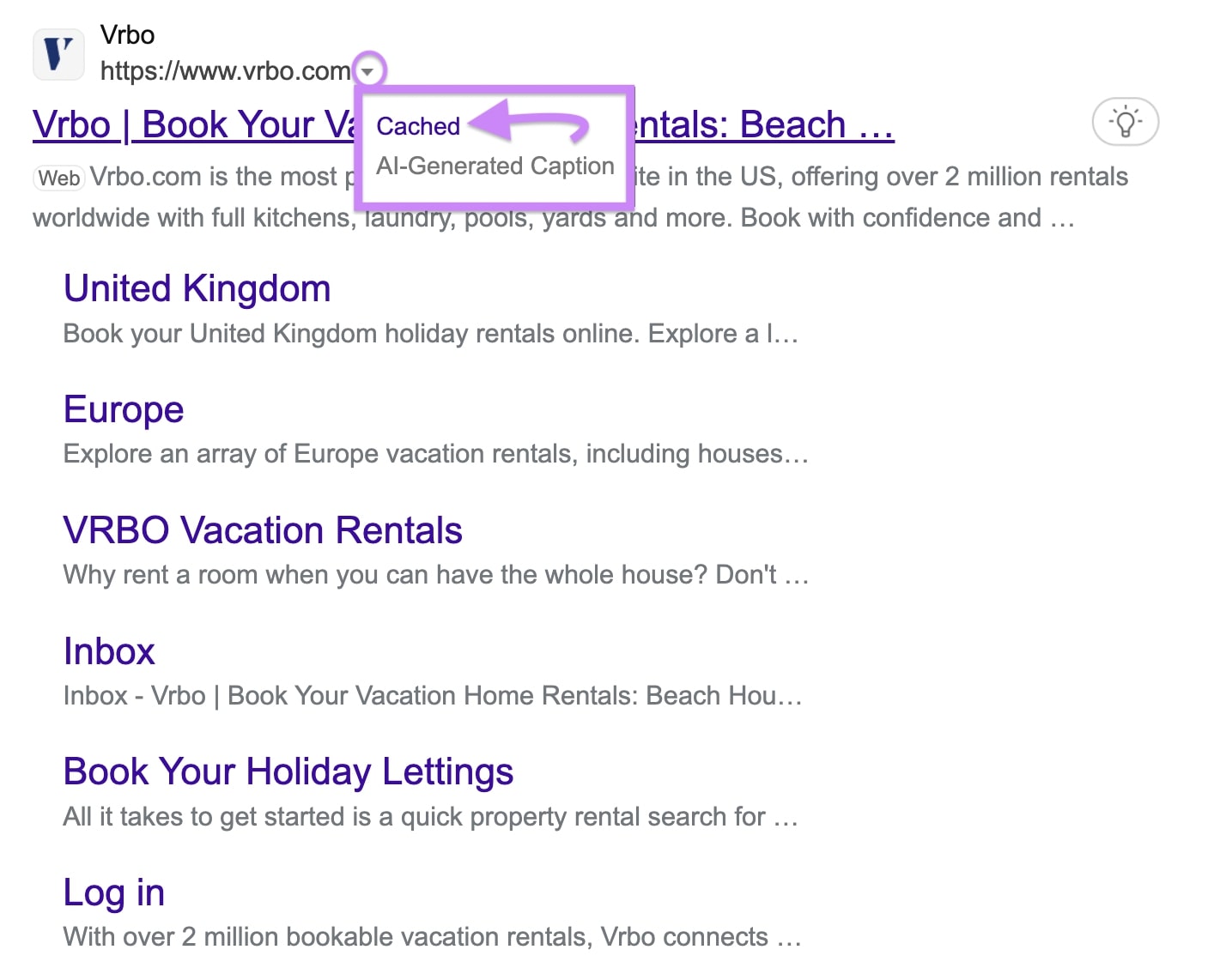
Right here’s the way to entry a cached model of a web page in Bing, for instance. You’ll discover the method acquainted if you know the way to view Google cached pages:
Navigate to Bing. Sort—or copy and paste—the web page’s URL into the search bar.
Find the web page’s search outcome on Bing’s SERP and click on the downward-pointing arrow subsequent to the web page’s URL.
Then, click on “Cached.”
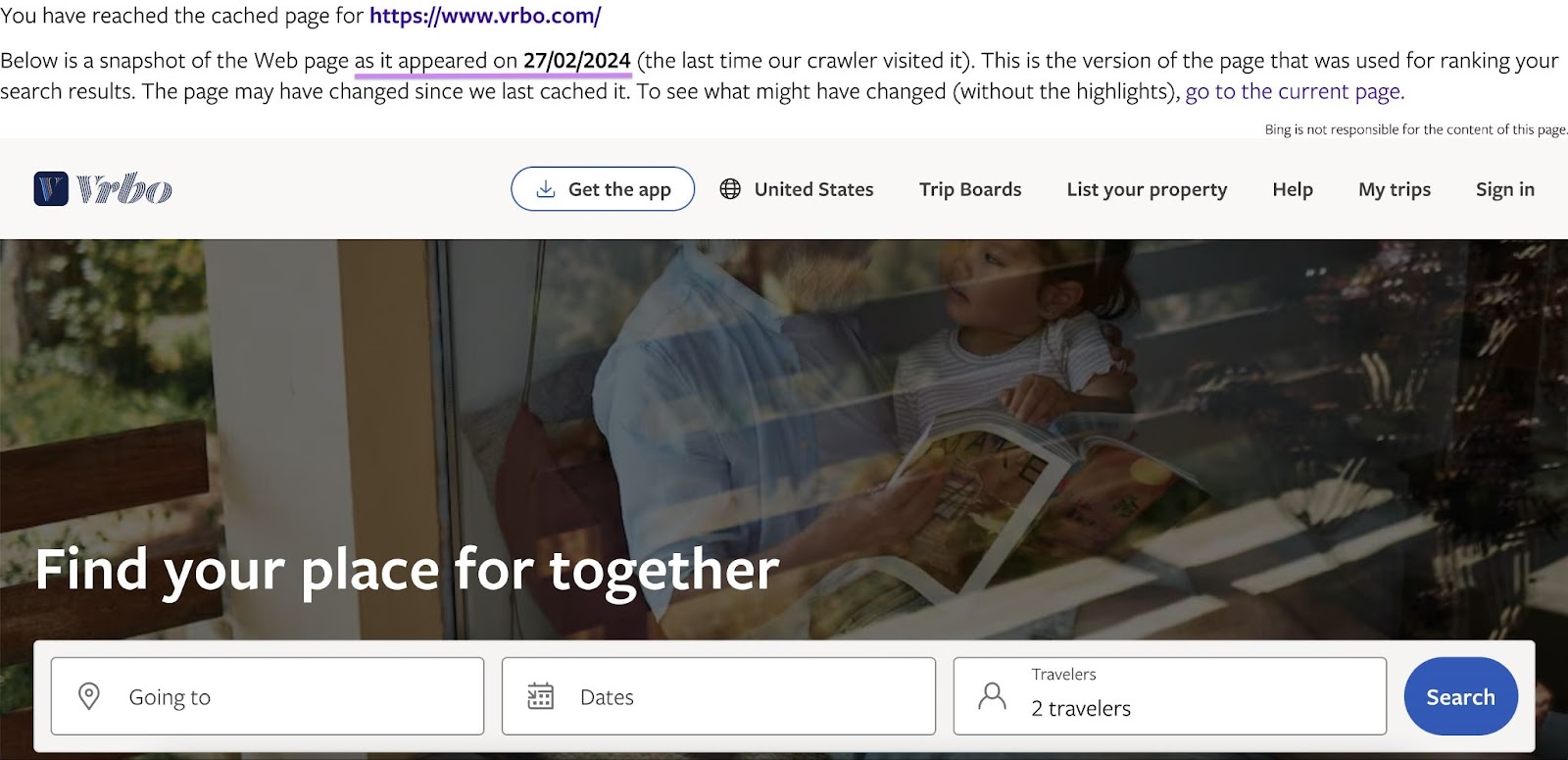
You’ll see Bing’s cached model of the web page. And knowledge on the date on which Bing created it.
Wayback Machine
Owned by Web Archive, Wayback Machine is an internet database of pages as they appeared on totally different dates.
It serves as a historic archive of the web, permitting customers to verify how pages appeared on varied dates. And monitor the adjustments to them over time.
In distinction, the caches of search engines like google (Google or in any other case) provide just one previous model of a web page—the web page’s look after they final cached it.
To make use of Wayback Machine, navigate to net.archive.org. Sort—or copy and paste—a web page’s URL into the search bar.
Hit “Enter” or “Return” in your keyboard to run the search.
If Wayback Machine has archived the web page at the very least as soon as, it’ll inform you when it first did so. And what number of copies of the web page it’s saved since then. Click on any yr within the timeline and the calendar will show the dates on which snapshots can be found for that yr.
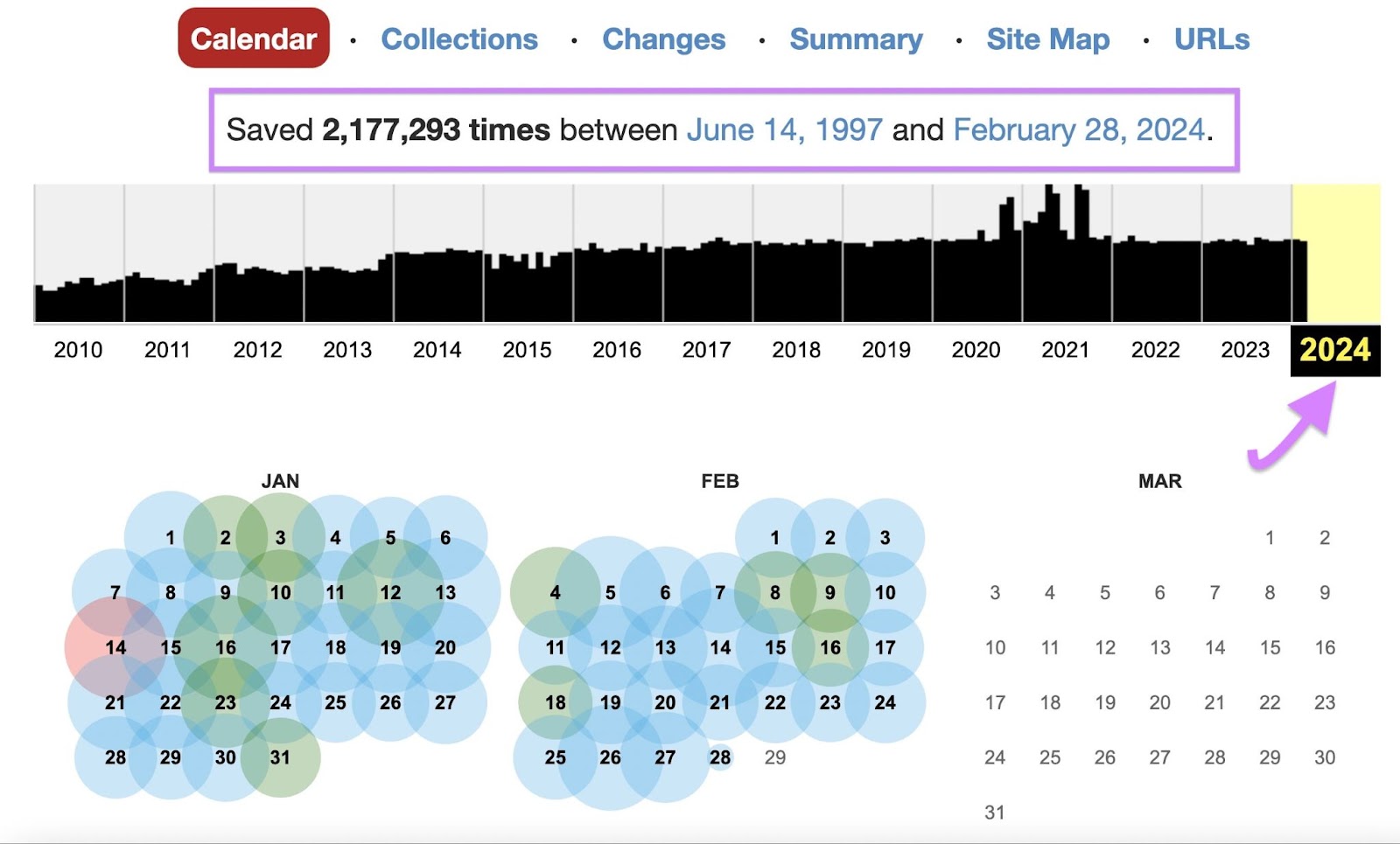
It should additionally show a calendar with coloured circles to point the dates on which it has saved at the very least one copy—or “snapshot”—of the web page.
Hover your cursor over any highlighted date to view a listing of timecodes at which Wayback Machine snapshotted the web page that day.
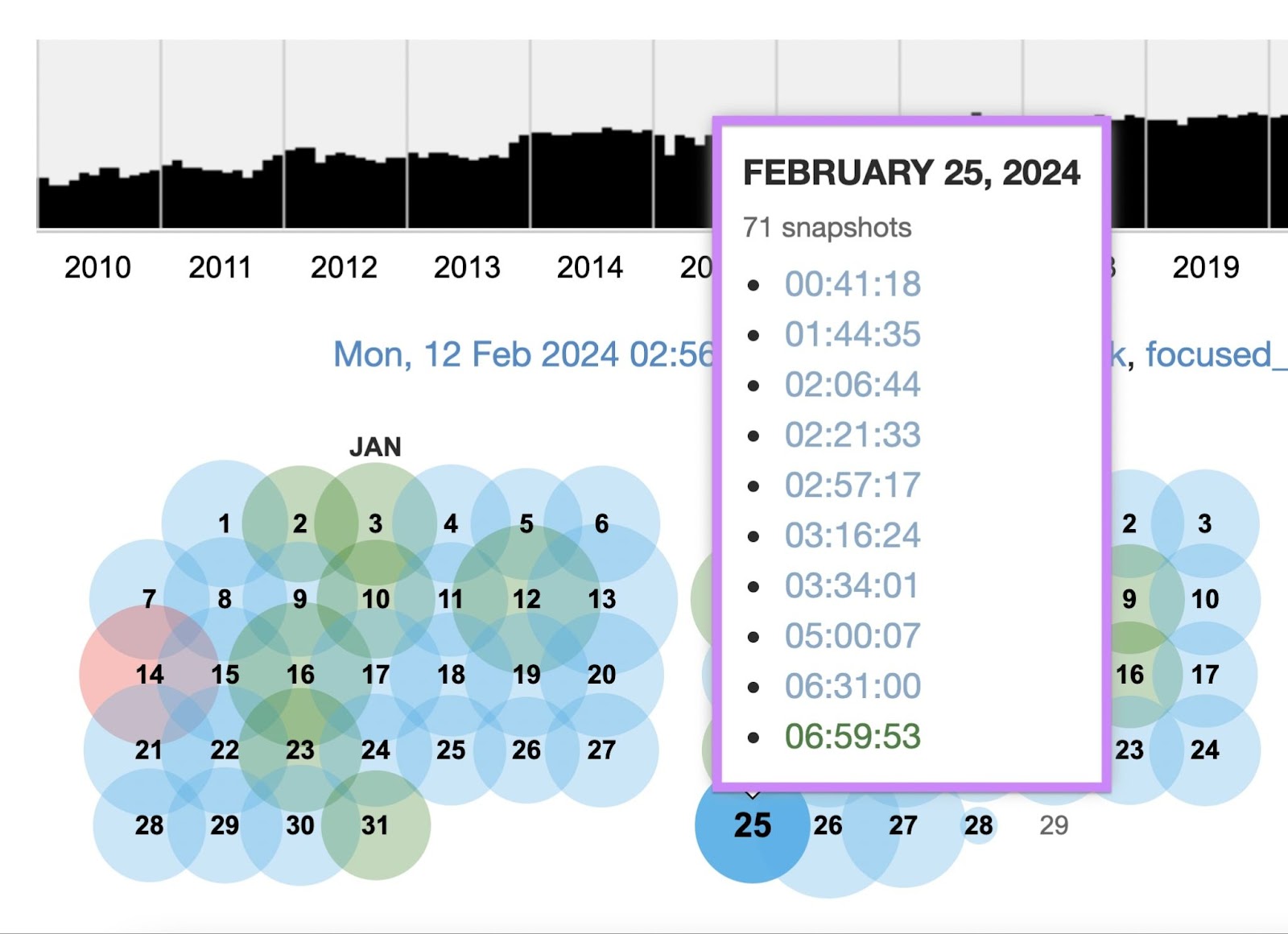
Click on any timecode on the listing to view its related snapshot.
Finest Practices for Site owners in a Put up-Google-Cache Period
Should you run or preserve an internet site, take these steps to mitigate the lack of Google’s cached pages:
View Pages Utilizing URL Inspection Instruments
As a substitute of trying to find cached pages on Google to learn the way the search engine noticed your pages when indexing them, use various instruments just like the URL Inspection Instrument and Wealthy Outcomes Take a look at instrument.
As talked about earlier, these instruments can present extra correct insights into how Google has listed your pages.
And, similar to Google’s “cached” function, you don’t want to attach your web site to any particular platform to make use of the Wealthy Outcomes Take a look at instrument.
Guarantee Your Web site Masses Reliably (and Shortly)
As customers now have one fewer workaround for looking unavailable or gradual webpages, it’s much more vital that your web site masses shortly and reliably.
Technical points, like an excessively excessive HTTP request depend, can decelerate a web page’s load velocity. Whereas others, like 404 errors, can stop it from loading in any respect. Use a instrument like Semrush’s Web site Audit to detect and repair these points, and schedule common checks to maintain them at bay.
Join a free Semrush account now to observe together with these steps.
To make use of Web site Audit, log in to your Semrush account and click on “web optimization” > “Web site Audit” within the left sidebar.
Click on “+ Create venture.”
Fill out your web site’s area (or subdomain) and an optionally available venture title within the “Create venture” window that seems. Then, click on “Create venture.”
Web site Audit will verify your area and its subdomains by default. Should you don’t want it to verify your subdomains, click on the pencil icon subsequent to the “Crawl scope” setting.
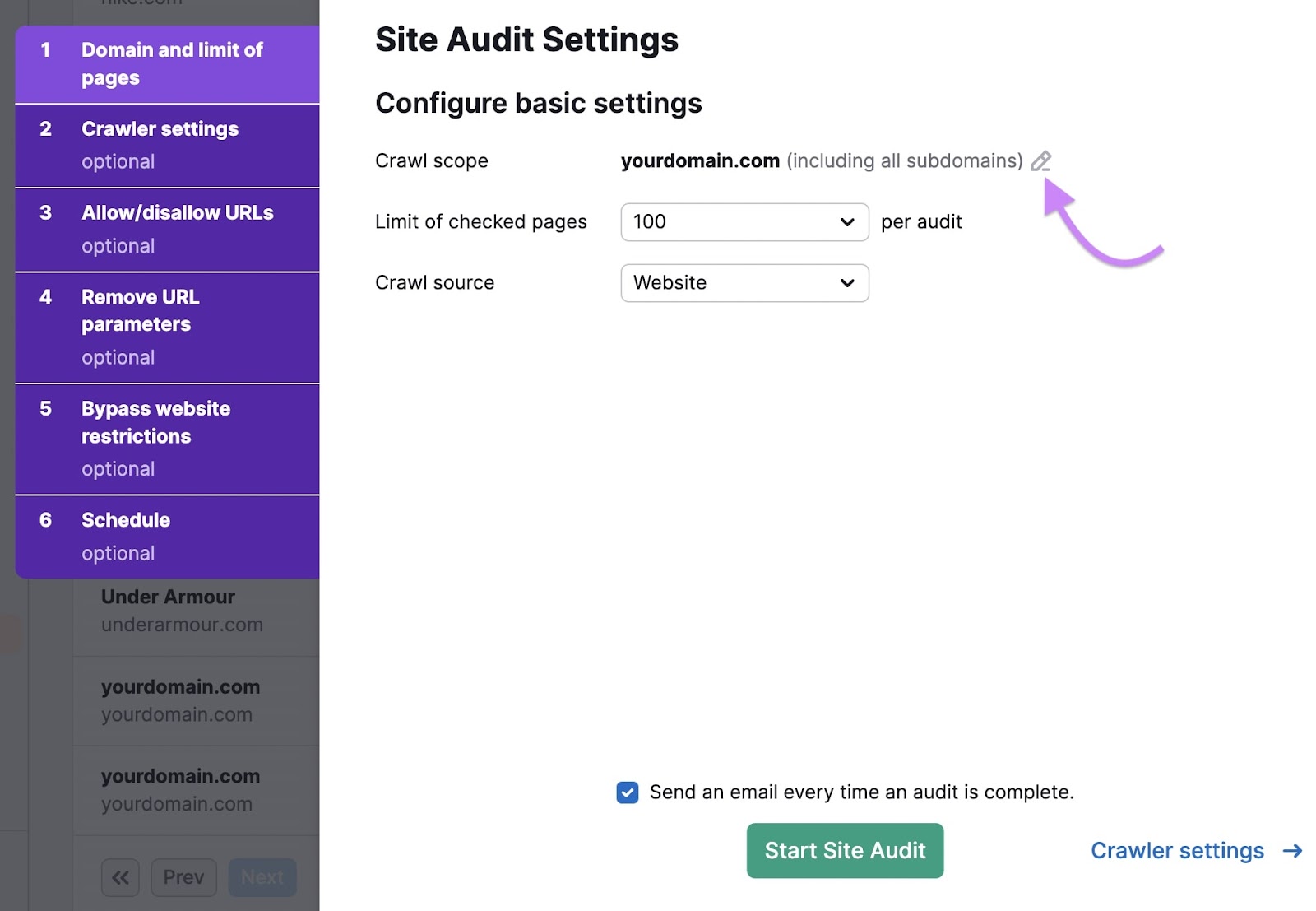
Uncheck the “Crawl all subdomains of [domain]” checkbox, after which click on “Save adjustments.”
![“Crawl all subdomains of [domain]” checkbox in Site Audit Settings](https://static.semrush.com/blog/uploads/media/98/18/9818c8213a884d1d16fd60c5250ee6ab/fbb44ae0ce283dbc96f54b1f94cea8f7/QlF1P-SCxF_P3ZLkwGp9DnY3HUAD4tGJHVANA9eFSLMJ9_G7dx-PWxehYQKPbSPRY31yXp4Xdaw0KGoyGToNgZuHVWkoG8ugs25iafzbyKfGDN2Y56yY9wmENr02KY3gExj6jX5NyStJFg13CdXHDoY.jpeg)
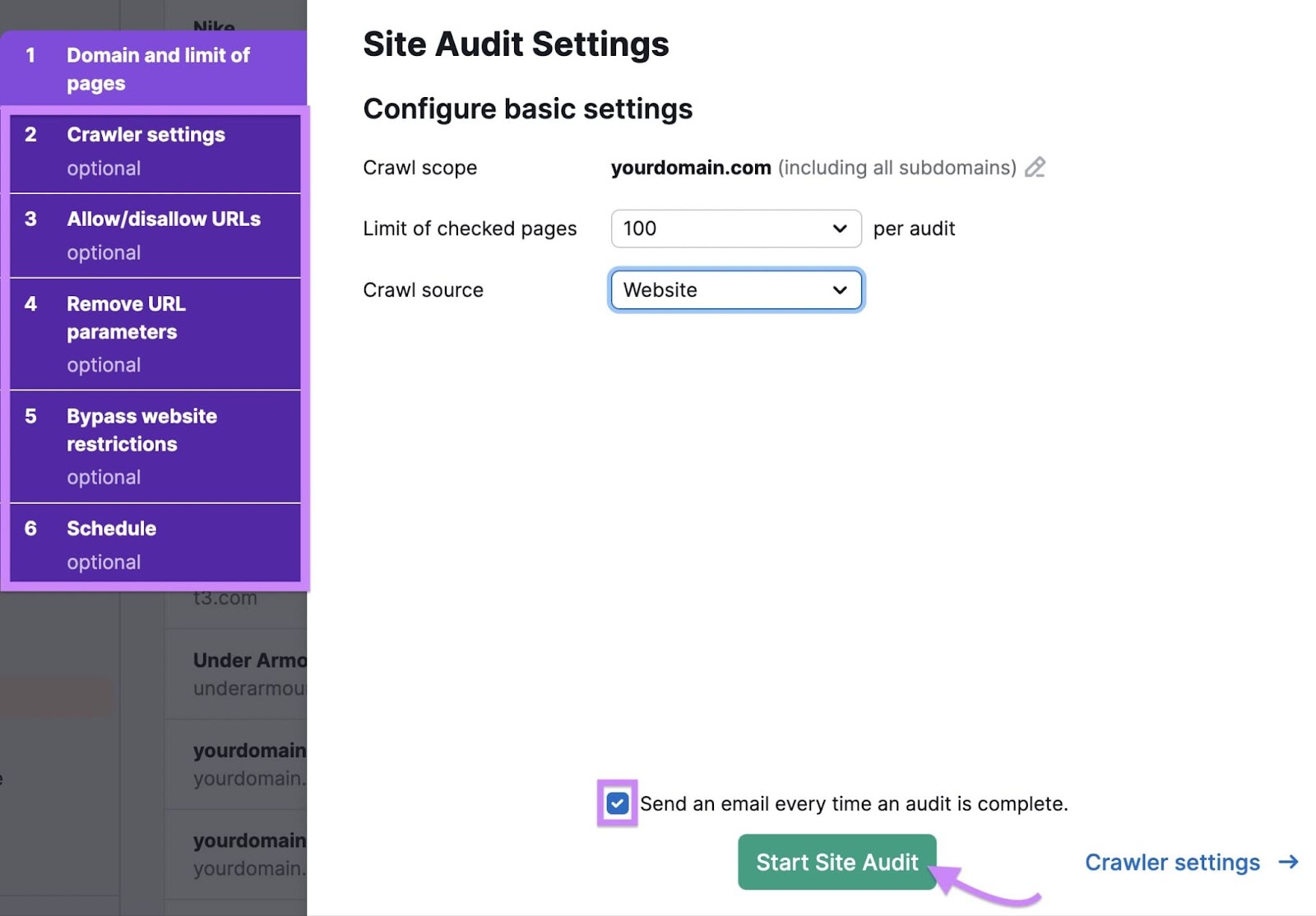
Subsequent, use the “Restrict of checked pages” setting to arrange the variety of pages Web site Audit ought to verify each time it runs. For instance, set the restrict to “100” if you wish to check the instrument earlier than operating it on all of your webpages.
Depart the “Crawl supply” setting as “Web site” to have Web site Audit verify your total web site.
By default, Web site Audit will e-mail you to let you already know when it has completed checking your web site. Should you don’t want this notification, uncheck the “Ship an e-mail each time an audit is full.” checkbox.
Non-compulsory: Use the tabs numbered two to 6 on the left to regulate settings like:
The URLs Web site Audit ought to (or shouldn’t) verify The URL parameters the instrument ought to ignore
Click on “Begin Web site Audit” whenever you’re carried out.
Web site Audit will scan your web site for points. After it has completed its checks, click on your (sub)area in your listing of tasks to view the total report.
Click on the “Points” tab.
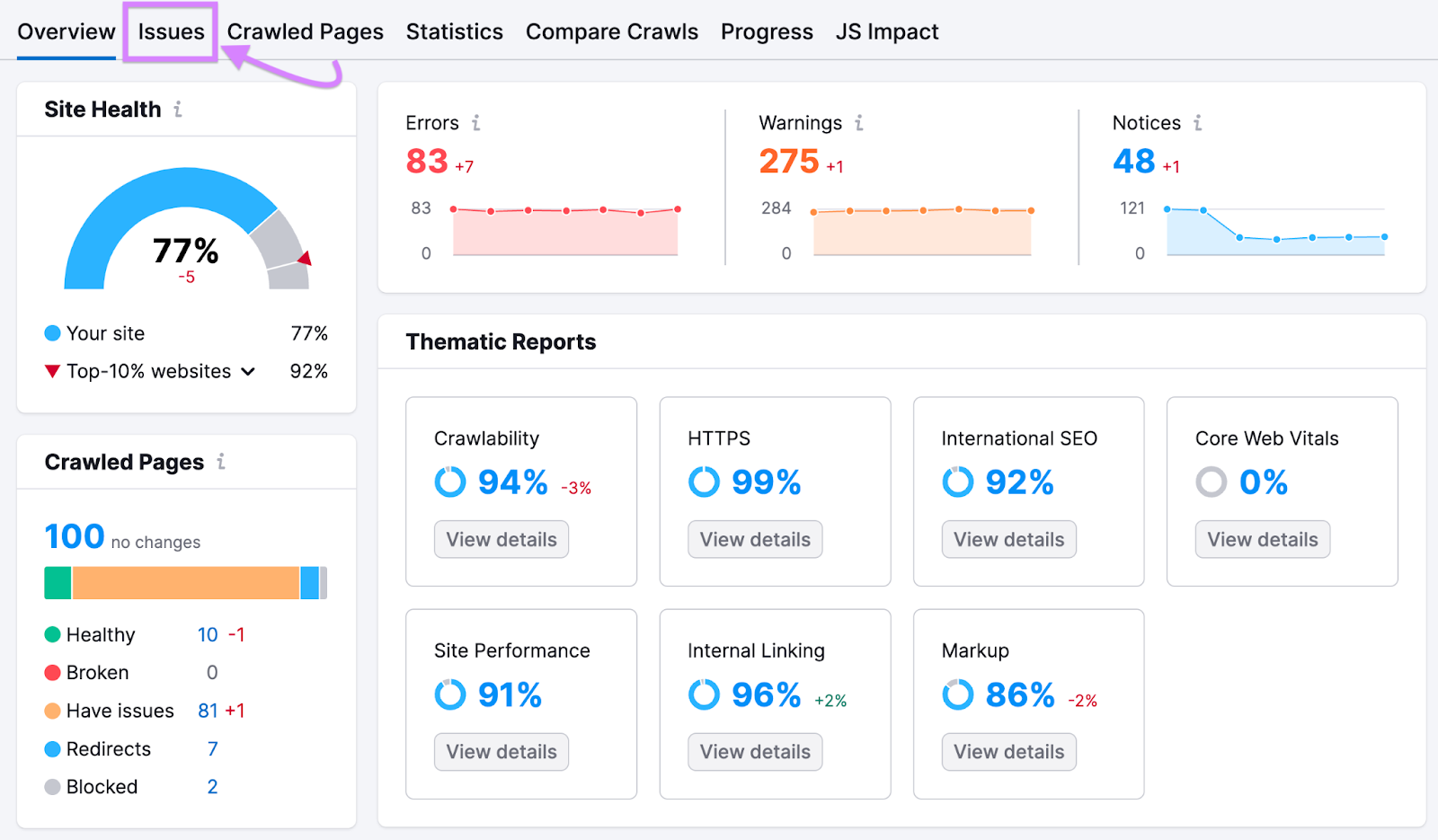
You’ll get a listing of:
Errors: Probably the most severe points that want pressing fixing Warnings: Points that aren’t as severe however should deserve consideration Notices: The least severe points that you could be contemplate fixing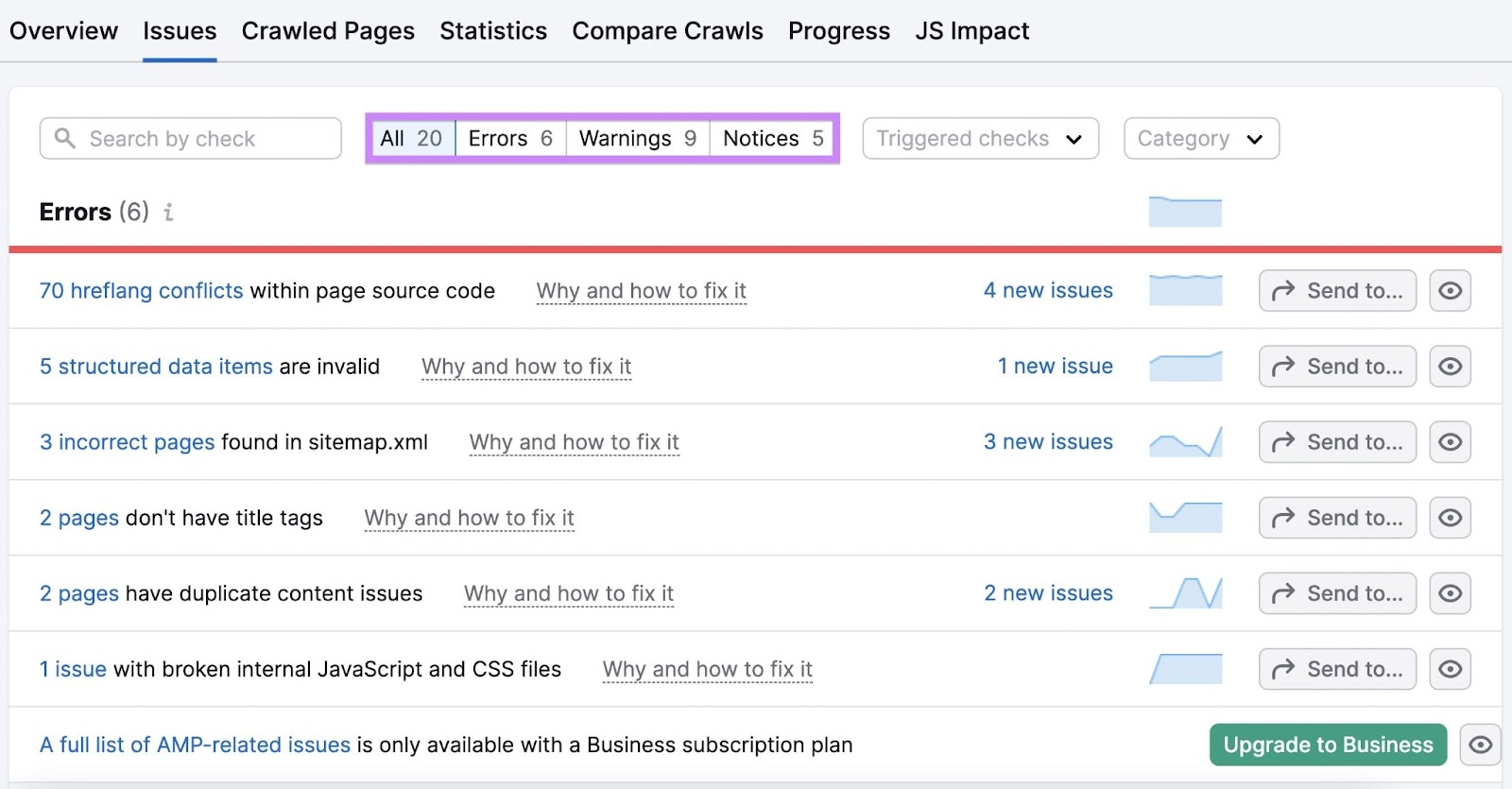
Web site Audit can detect over 140 technical points in all. Particularly, look out for these errors. They might affect your web site’s loading capacity and velocity:
“# pages returned 4XX standing code”: These pages have a 4XX error—like a 404 error—stopping customers from accessing them “# pages couldn’t be crawled (DNS decision points)”: These pages have Area Identify System (DNS) errors that stop Web site Audit from accessing the server on which they’re hosted. On this case, customers probably can’t view them both “# pages have gradual load velocity”: These pages take a very long time to load
Click on the hyperlinked “# pages” textual content for any of those errors to see the pages experiencing them.
For instance, right here’s what you’ll see whenever you click on to view the pages that returned 4XX standing codes:
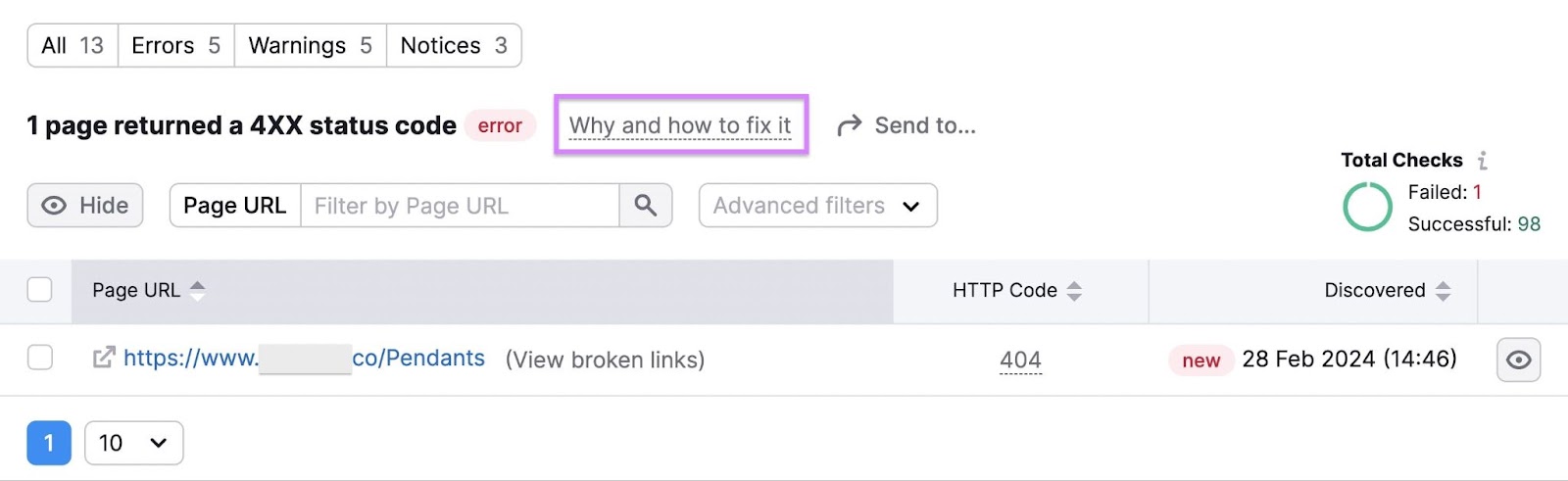
Then, deal with the detected points. Click on the “Why and the way to repair it” textual content subsequent to every error to get steerage on fixing it.
These articles might also be helpful:
If doubtful, contact an online developer for assist.
Web site Audit may scan your web site repeatedly. So that you keep on high of any new points that crop up.
Click on the gear icon on the high of the Web site Audit report. Scroll down the listing of settings beneath “Web site Audit settings” and click on “Schedule: Weekly, Each Tuesday,” (or no matter day it’s you are taking a look at this report).
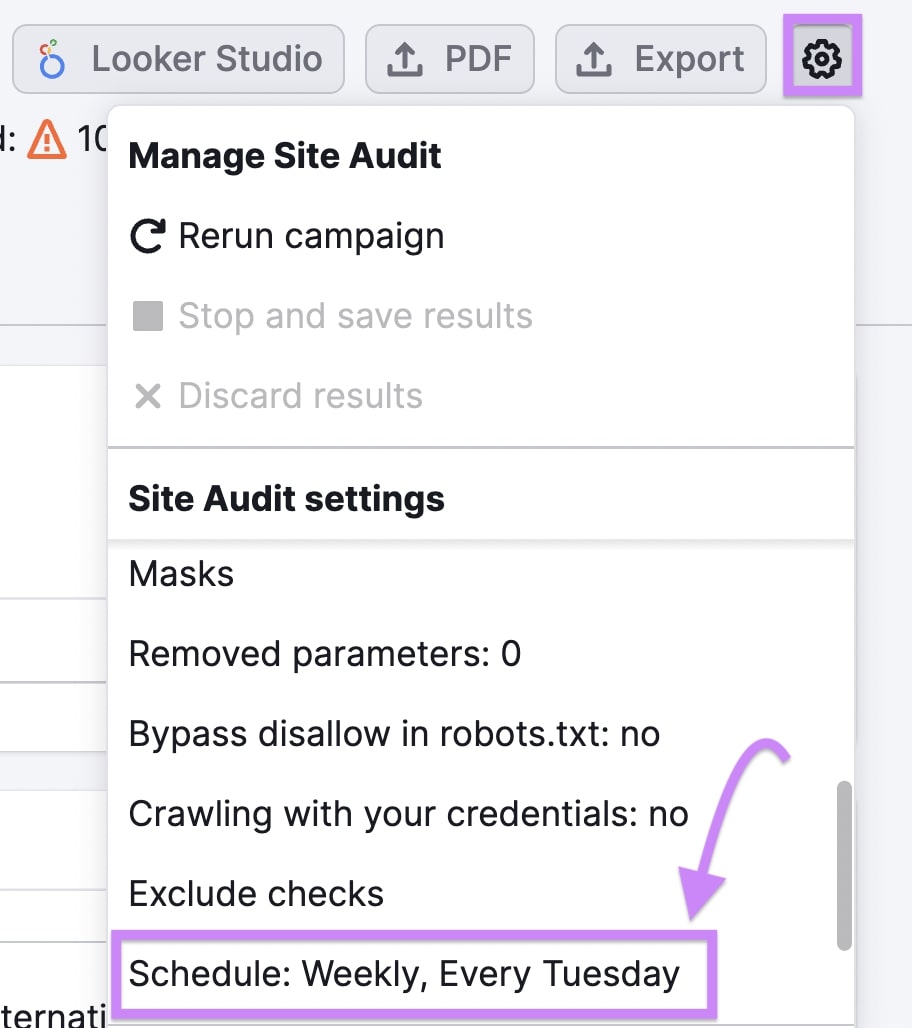
Select whether or not Web site Audit ought to scan your web site each day, weekly, or month-to-month. Then, click on “Save” to arrange your computerized scan schedule.
The Way forward for Net Content material Preservation
With the discontinuation of Google’s “cached” function, web archival platforms like Wayback Machine could play a bigger position in preserving a historic document of the net.
Why?
As a result of these platforms doc adjustments to a web page’s content material over time. In contrast to different search engines like google’ caches, which solely let customers view the most recent model of a cached web page.
Wayback Machine stands to grow to be an much more outstanding archival service if it will get an official tie-up with Google.
Though he makes no guarantees at the moment, Google’s Danny Sullivan has expressed curiosity in changing the search engine’s cached hyperlinks with hyperlinks to Wayback Machine:
Personally, I hope that perhaps we’ll add hyperlinks to [Wayback Machine] from the place we had the cache hyperlink earlier than, inside About This Outcome. It is such a tremendous useful resource. For the knowledge literacy purpose of About The Outcome, I believe it will even be a pleasant match — permitting folks to simply see how a web page modified over time. No guarantees. We now have to speak to them, see the way it all would possibly go — entails folks properly past me. However I believe it will be good throughout.
Learn how to Forestall Caching
Though Google’s “cached” function goes away, different platforms like Bing and Wayback Machine should cache your pages.
Attempt these choices in case you don’t need them to.
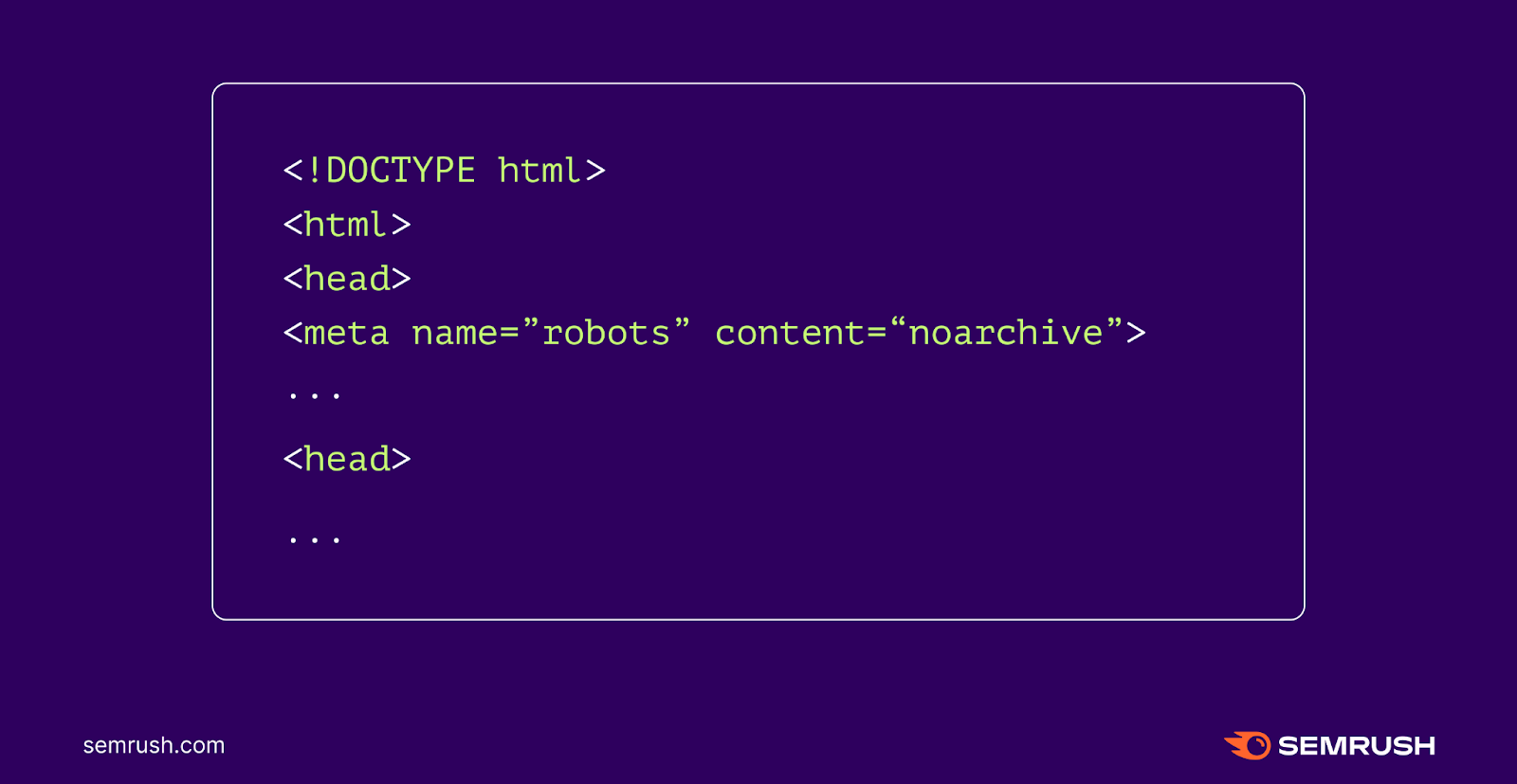
Use the ‘Noarchive’ Meta Robots Tag
The “noarchive” meta robots tag is a code snippet you may add to a web page to inform a platform to not cache it. Because of this, customers received’t have the ability to entry a cached model of the web page.
The tag seems like this:
<meta title=”robots” content material=”noarchive”>
Add this tag to the <head> part of each web page you wish to preserve out of others’ caches. Like so:
Submit a Request To not Be Cached
Some platforms present a proper process for opting out of their cache. If that’s the case, observe it even in case you’ve already added the “noarchive” tag to your pages.
That’s as a result of the platform could not verify for the “noarchive” tag when caching your pages. Alternatively, it could exclude your pages from its cache solely whenever you make a proper request.
To request that Wayback Machine doesn’t cache your pages, for instance, ship an e-mail to data@archive.org with info like:
The web page URL(s) you don’t need Wayback Machine to cache The interval for which the platform shouldn’t cache your pages
Wayback Machine will evaluate your request and determine whether or not to comply with it.
No Google Cached Pages? No Drawback
Regardless that we have now to say goodbye to Google’s cached pages, there are alternate options for its varied features.
For instance, there’s the URL Inspection Instrument and Wealthy Outcomes Take a look at instrument if you wish to verify how Google noticed your pages when indexing them.
And if customers have bother loading your web page, they’ll verify its cached model in different search engines like google’ caches or on Wayback Machine.
That mentioned, it’s finest if customers can reliably entry your web site within the first place.
Semrush’s Web site Audit offers monitoring of your web site for technical points. So that you grow to be conscious of—and might promptly repair—people who preserve customers from accessing your web site.
Attempt Web site Audit by signing up for a free Semrush account.
[ad_2]
Supply hyperlink

