
[ad_1]

Illustration by Ada Zielińska
In 2022, Pratyusha Ria Kalluri, a graduate scholar in synthetic intelligence (AI) at Stanford College in California, discovered one thing alarming in image-generating AI applications. When she prompted a preferred instrument for ‘a photograph of an American man and his home’, it generated a picture of a pale-skinned particular person in entrance of a giant, colonial-style residence. When she requested for ‘a photograph of an African man and his fancy home’, it produced a picture of a dark-skinned particular person in entrance of a easy mud home — regardless of the phrase ‘fancy’.
After some digging, Kalluri and her colleagues discovered that photographs generated by the favored instruments Secure Diffusion, launched by the agency Stability AI, and DALL·E, from OpenAI, overwhelmingly resorted to frequent stereotypes, akin to associating the phrase ‘Africa’ with poverty, or ‘poor’ with darkish pores and skin tones. The instruments they studied even amplified some biases. For instance, in photographs generated from prompts asking for pictures of individuals with sure jobs, the instruments portrayed nearly all housekeepers as folks of color and all flight attendants as ladies, and in proportions which can be a lot larger than the demographic actuality (see ‘Amplified stereotypes’)1. Different researchers have discovered comparable biases throughout the board: text-to-image generative AI fashions usually produce photographs that embrace biased and stereotypical traits associated to gender, pores and skin color, occupations, nationalities and extra.
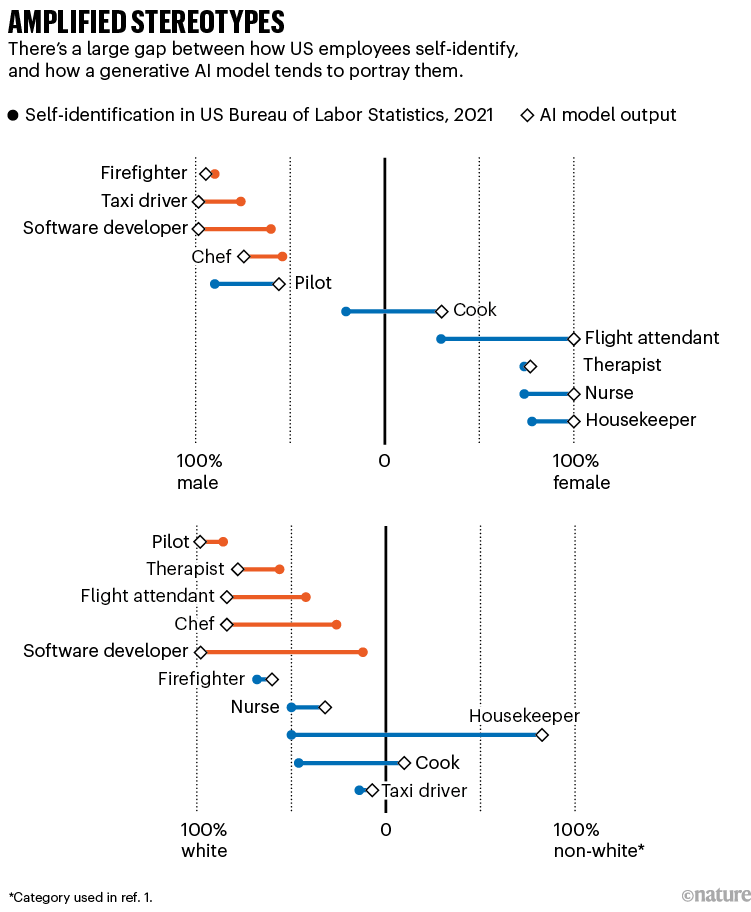
Supply: Ref. 1
Maybe that is unsurprising, on condition that society is filled with such stereotypes. Research have proven that photographs utilized by media retailers2, world well being organizations3 and Web databases akin to Wikipedia4usually have biased representations of gender and race. AI fashions are being educated on on-line footage that aren’t solely biased however that additionally typically include unlawful or problematic imagery, akin to images of kid abuse or non-consensual nudity. They form what the AI creates: in some circumstances, the photographs created by picture mills are even much less various than the outcomes of a Google picture search, says Kalluri. “I believe a lot of folks ought to discover that very hanging and regarding.”
This drawback issues, researchers say, as a result of the rising use of AI to generate photographs will additional exacerbate stereotypes. Though some customers are producing AI photographs for enjoyable, others are utilizing them to populate web sites or medical pamphlets. Critics say that this challenge ought to be tackled now, earlier than AI turns into entrenched. Loads of experiences, together with the 2022 Advice on the Ethics of Synthetic Intelligence from the United Nations cultural group UNESCO, spotlight bias as a number one concern.
Some researchers are centered on educating folks easy methods to use these instruments higher, or on understanding methods to enhance curation of the coaching knowledge. However the discipline is rife with issue, together with uncertainty about what the ‘proper’ final result ought to be. An important step, researchers say, is to open up AI methods so that folks can see what’s happening beneath the hood, the place the biases come up and the way finest to squash them. “We have to push for open sourcing. If lots of the information units aren’t open supply, we don’t even know what issues exist,” says Abeba Birhane, a cognitive scientist on the Mozilla Basis in Dublin.
Make me an image
Picture mills first appeared in 2015, when researchers constructed alignDRAW, an AI mannequin that would generate blurry photographs primarily based on textual content enter5. It was educated on a knowledge set containing round 83,000 photographs with captions. As we speak, a swathe of picture mills of various talents are educated on knowledge units containing billions of photographs. Most instruments are proprietary, and the small print of which photographs are fed into these methods are sometimes saved beneath wraps, together with precisely how they work.

This picture, generated from a immediate for “an African man and his fancy home”, reveals among the typical associations between ‘African’ and ‘poverty’ in lots of generated photographs.Credit score: P. Kalluri et al. generated utilizing Secure Diffusion XL
Generally, these mills study to attach attributes akin to color, form or model to varied descriptors. When a person enters a immediate, the generator builds new visible depictions on the idea of attributes which can be near these phrases. The outcomes will be each surprisingly lifelike and, usually, unusually flawed (palms typically have six fingers, for instance).
The captions on these coaching photographs — written by people or mechanically generated, both when they’re first uploaded to the Web or when knowledge units are put collectively — are essential to this course of. However this info is commonly incomplete, selective and thus biased itself. A yellow banana, for instance, would most likely be labelled merely as ‘a banana’, however an outline for a pink banana could be prone to embrace the color. “The identical factor occurs with pores and skin color. White pores and skin is taken into account the default so it isn’t sometimes talked about,” says Kathleen Fraser, an AI analysis scientist on the Nationwide Analysis Council in Ottawa, Canada. “So the AI fashions study, incorrectly on this case, that after we use the phrase ‘pores and skin color’ in our prompts, we would like darkish pores and skin colors,” says Fraser.
The problem with these AI methods is that they’ll’t simply miss ambiguous or problematic particulars of their generated photographs. “When you ask for a physician, they’ll’t miss the pores and skin tone,” says Kalluri. And if a person asks for an image of a sort particular person, the AI system has to visualise that by some means. “How they fill within the blanks leaves lots of room for bias to creep in,” she says. It is a drawback that’s distinctive to picture era — in contrast, an AI textual content generator might create a language-based description of a physician with out ever mentioning gender or race, as an illustration; and for a language translator, the enter textual content could be ample.
Do it your self
One generally proposed method to producing various photographs is to put in writing higher prompts. For example, a 2022 examine discovered that including the phrase “if all people will be [X], regardless of gender” to a immediate helps to cut back gender bias within the photographs produced6.
However this doesn’t at all times work as meant. A 2023 examine by Fraser and her colleagues discovered that such intervention typically exacerbated biases7. Including the phrase “if all people will be felons regardless of pores and skin color”, for instance, shifted the outcomes from principally dark-skinned folks to all dark-skinned folks. Even express counter-prompts can have unintended results: including the phrase ‘white’ to a immediate for ‘a poor particular person’, for instance, typically resulted in photographs through which generally related options of whiteness, akin to blue eyes, have been added to dark-skinned faces.

In a Lancet examine of world well being photographs, the immediate “Black African physician helps poor and sick white kids, photojournalism” produced this picture, which reproduced the ‘white saviour’ trope they have been explicitly making an attempt to counteract.Credit score: A. Alenichev et al. generated utilizing Midjourney
One other frequent repair is for customers to direct outcomes by feeding in a handful of photographs which can be extra just like what they’re searching for. The generative AI program Midjourney, as an illustration, permits customers so as to add picture URLs within the immediate. “However it actually looks like each time establishments do that they’re actually enjoying whack-a-mole,” says Kalluri. “They’re responding to at least one very particular form of picture that folks wish to have produced and probably not confronting the underlying drawback.”
These options additionally unfairly put the onus on the customers, says Kalluri, particularly those that are under-represented within the knowledge units. Moreover, loads of customers won’t be fascinated with bias, and are unlikely to pay to run a number of queries to get more-diverse imagery. “When you don’t see any variety within the generated photographs, there’s no monetary incentive to run it once more,” says Fraser.
Some firms say they add one thing to their algorithms to assist counteract bias with out person intervention: OpenAI, for instance, says that DALL·E2 makes use of a “new approach” to create extra variety from prompts that don’t specify race or gender. However it’s unclear how such methods work they usually, too, might have unintended impacts. In early February, Google launched a picture generator that had been tuned to keep away from some typical image-generator pitfalls. A media frenzy ensued when person prompts requesting an image of a ‘1943 German soldier’ created photographs of Black and Asian Nazis — a various however traditionally inaccurate end result. Google acknowledged the error and quickly stopped its generator creating photographs of individuals.
Information clean-up
Alongside such efforts lie makes an attempt to enhance curation of coaching knowledge units, which is time-consuming and costly for these containing billions of photographs. Which means firms resort to automated filtering mechanisms to take away undesirable knowledge.

AI-generated photographs and video are right here: how might they form analysis?
Nevertheless, automated filtering primarily based on key phrases doesn’t catch all the pieces. Researchers together with Birhane have discovered, for instance, that benign key phrases akin to ‘daughter’ and ‘nun’ have been used to tag sexually express photographs in some circumstances, and that photographs of schoolgirls are typically tagged with phrases looked for by sexual predators8. And filtering, too, can have unintended results. For instance, automated makes an attempt to wash massive, text-based knowledge units have eliminated a disproportionate quantity of content material created by and for people from minority teams9. And OpenAI found that its broad filters for sexual and violent imagery in DALL·E2 had the unintended impact of making a bias in opposition to the era of photographs of girls, as a result of ladies have been disproportionately represented in these photographs.
One of the best curation “requires human involvement”, says Birhane. However that’s sluggish and costly, and taking a look at many such photographs takes a deep emotional toll, as she nicely is aware of. “Generally it simply will get an excessive amount of.”
Impartial evaluations of the curation course of are impeded by the truth that these knowledge units are sometimes proprietary. To assist overcome this drawback, LAION, a non-profit group in Hamburg, Germany, has created publicly accessible machine-learning fashions and knowledge units that hyperlink to pictures and their captions, in an try to duplicate what goes on behind the closed doorways of AI firms. “What they’re doing by placing collectively the LAION knowledge units is giving us a glimpse into what knowledge units inside huge firms and corporations like OpenAI appear to be,” says Birhane. Though meant for analysis use, these knowledge units have been used to coach fashions akin to Secure Diffusion.

Citations present gender bias — and the explanations are stunning
Researchers have learnt from interrogating LAION knowledge that larger isn’t at all times higher. AI researchers usually assume that the larger the coaching knowledge set, the extra probably that biases will disappear, says Birhane. “Individuals usually declare that scale cancels out noise,” she says. “The truth is, the nice and the dangerous don’t steadiness out.” In a 2023 examine, Birhane and her crew in contrast the information set LAION-400M, which has 400 million picture hyperlinks, with LAION-2B-en, which has 2 billion, and located that hate content material within the captions elevated by round 12% within the bigger knowledge set10, most likely as a result of extra low-quality knowledge had slipped by way of.
An investigation by one other group discovered that the LAION-5B knowledge set contained baby sexual abuse materials. Following this, LAION took down the information units. A spokesperson for LAION informed Nature that it’s working with the UK charity Web Watch Basis and the Canadian Centre for Youngster Safety in Winnipeg to determine and take away hyperlinks to unlawful supplies earlier than it republishes the information units.
Open or shut
If LAION is bearing the brunt of some dangerous press, that’s maybe as a result of it’s one of many few open knowledge sources. “We nonetheless don’t know loads concerning the knowledge units which can be created inside these company firms,” says Will Orr, who research cultural practices of information manufacturing on the College of Southern California in Los Angeles. “They are saying that it’s to do with this being proprietary data, however it’s additionally a approach to distance themselves from accountability.”
In response to Nature’s questions on which measures are in place to take away dangerous or biased content material from DALL·E’s coaching knowledge set, OpenAI pointed to publicly accessible experiences that define its work to cut back gender and racial bias, with out offering precise particulars on how that’s completed. Stability AI and Midjourney didn’t reply to Nature’s e-mails.
Orr interviewed some knowledge set creators from know-how firms, universities and non-profit organizations, together with LAION, to know their motivations and the constraints. “A few of these creators had emotions that they weren’t in a position to current all the restrictions of the information units,” he says, as a result of that is perhaps perceived as important weaknesses that undermine the worth of their work.

How journals are combating again in opposition to a wave of questionable photographs
Specialists really feel that the sector nonetheless lacks standardized practices for annotating their work, which might assist to make it extra open to scrutiny and investigation. “The machine-learning neighborhood has not traditionally had a tradition of satisfactory documentation or logging,” says Deborah Raji, a Mozilla Basis fellow and laptop scientist on the College of California, Berkeley. In 2018, AI ethics researcher Timnit Gebru — a robust proponent of accountable AI and co-founder of the neighborhood group Black in AI — and her crew launched a datasheet to standardize the documentation course of for machine-learning knowledge units11. The datasheet has greater than 50 inquiries to information documentation concerning the content material, assortment course of, filtering, meant makes use of and extra.
The datasheet “was a extremely important intervention”, says Raji. Though many teachers are more and more adopting such documentation practices, there’s no incentive for firms to be open about their knowledge units. Solely rules can mandate this, says Birhane.
One instance is the European Union’s AI Act, which was endorsed by the European Parliament on 13 March. As soon as it turns into regulation, it can require that builders of high-risk AI methods present technical documentation, together with datasheets describing the coaching knowledge and strategies, in addition to particulars concerning the anticipated output high quality and potential discriminatory impacts, amongst different info. However which fashions will come beneath the high-risk classification stays unclear. If handed, the act would be the first complete regulation for AI know-how and can form how different nations take into consideration AI legal guidelines.
Specialists akin to Birhane, Fraser and others suppose that express and well-informed rules will push firms to be extra cognizant of how they construct and launch AI instruments. “Plenty of the coverage focus for image-generation work has been oriented round minimizing misinformation, misrepresentation and fraud by way of the usage of these photographs, and there was little or no, if any, concentrate on bias, performance or efficiency,” says Raji.
Even with a concentrate on bias, nevertheless, there’s nonetheless the query of what the perfect output of AI ought to be, researchers say — a social query with no easy reply. “There may be not essentially settlement on what the so-called proper reply ought to appear to be,” says Fraser. Do we would like our AI methods to replicate actuality, even when the fact is unfair? Or ought to it symbolize traits akin to gender and race in an even-handed, 50:50 means? “Somebody has to resolve what that distribution ought to be,” she says.
[ad_2]
Supply hyperlink

